Baidu Releases Unlimited OCR, a 3B Model That Keeps the KV Cache Flat for Long-Document Parsing
重點摘要
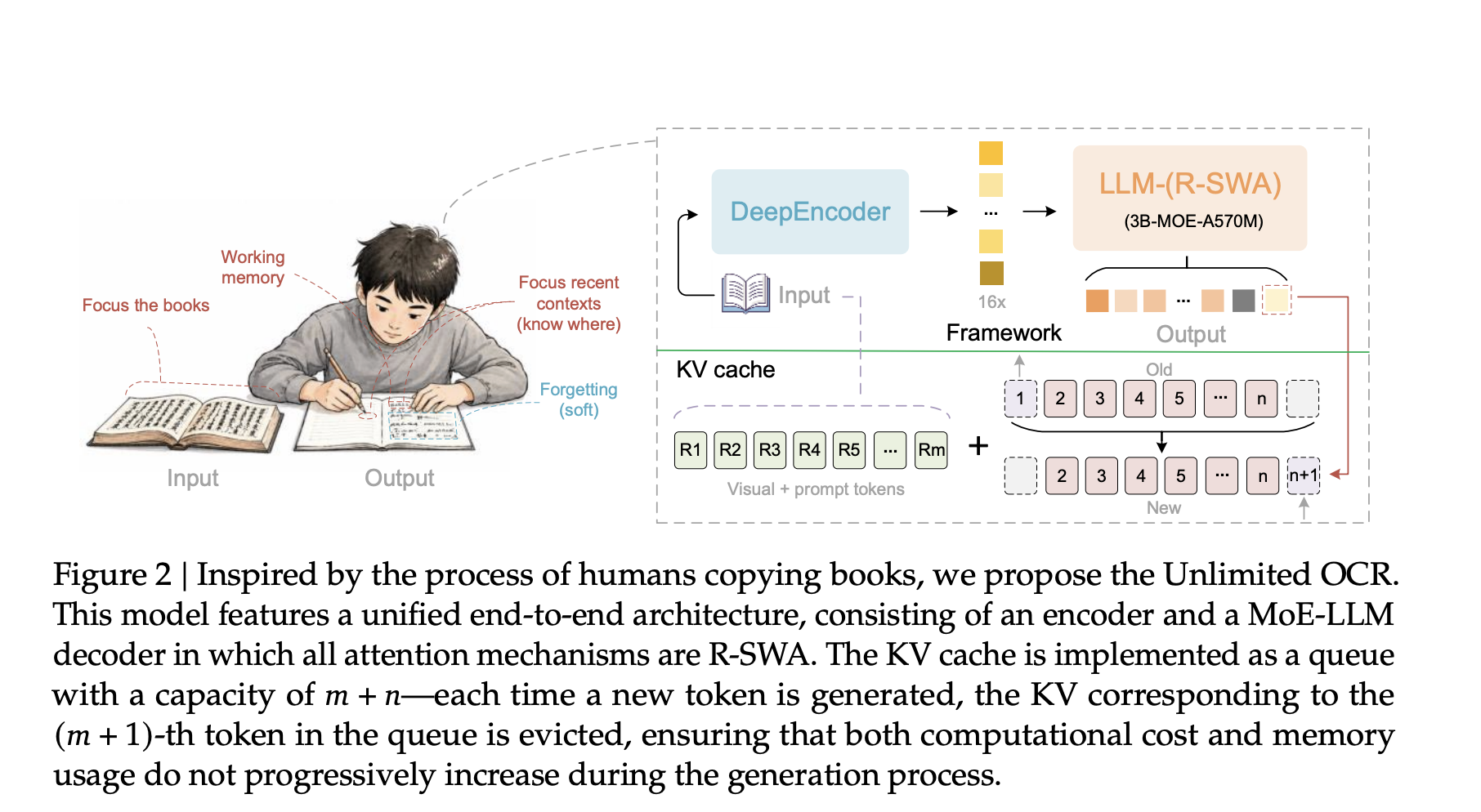
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant. TL;DR Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active. It replaces decoder attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant. The model parses dozens of pages in one forward pass under a 32K maximum length. It scores 93.23 on OmniDocBench v1.5, beating the DeepSeek OCR baseline by 6.22 points. It builds on DeepSeek OCR via continue-training, not a from-scratch run. What is Unlimited OCR? Unlimited OCR takes DeepSeek
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant. TL;DR Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active. It replaces decoder attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant. The model parses dozens of pages in one forward pass under a 32K maximum length. It scores 93.23 on OmniDocBench v1.5, beating the DeepSeek OCR baseline by 6.22 points. It builds on DeepSeek OCR via continue-training, not a from-scratch run. What is Unlimited OCR? Unlimited OCR takes DeepSeek OCR as its baseline. It keeps the DeepEncoder and the Mixture-of-Experts decoder. The MoE design holds 3B total parameters but activates only 500M at inference. The DeepEncoder is the compression engine. It cascades a SAM-ViT under window attention with a CLIP-ViT under global attention. At the bridge, it applies 16× token compression. A 1024×1024 PDF image becomes just 256 visual tokens. Fewer input tokens mean a smaller prefill. DeepEncoder natively supports five resolution modes, and Unlimited OCR keeps two. ‘Base’ mode runs at 1024×1024 for multi-page work. ‘Gundam’ mode uses dynamic resolution for single pages. https://arxiv.org/pdf/2606.23050 How R-SWA Keeps the Cache Constant The contribution is Reference Sliding Window Attention. Standard Multi-Head Attention stores a key and value for every token. As output length T grows, the cache grows with it. The size is CMHA(T) = Lm + T. Memory and latency climb without bound. R-SWA breaks that link. Each generated token attends to all reference tokens, meaning the visual tokens and the prompt. It also attends to the preceding n output tokens, where n defaults to 128. Everything older is evicted. The cache becomes a fixed queue of size m + n. The size is CR-SWA(T) = Lm + min(n, T) ≤ Lm + n. It is bounded by a constant. As T grows far beyond n, the cache ratio trends toward zero. So memory stays flat and per-step latency stays flat. The research team compare this to soft forgetting. A person copying a book glances at the source and the last few words. They do not re-read everything transcribed so far. Visual tokens never undergo state updates. That avoids the progressive blurring seen in linear attention. The interactive simulator below lets you vary T and watch both caches respond. Animate decoding</button> <button id="reset">Reset</button> </div> <div class="cards"> <div class="card mha"> <div class="k">MHA KV cache</div> <div class="v" id="mhaVal">10,048</div> <div class="u">key/value entries</div> </div> <div class="card swa"> <div class="k">R-SWA KV cache</div> <div class="v" id="swaVal">2,176</div> <div class="u">key/value entries</div> </div> <div class="card"> <div class="k">Cache ratio ρ</div> <div class="v" id="ratioVal">0.217</div> <div class="u">R-SWA ÷ MHA</div> </div> <div class="card"> <div class="k">Memory saved</div> <div class="v" id="saveVal">78%</div> <div class="u">vs standard MHA</div> </div> </div> <div class="bars"> <div class="bar-label"><span>Standard MHA — grows with every token</span><b id="mhaBarTxt">10,048</b></div> <div class="bar-track"><div class="bar-fill mha" id="mhaBar" style="width:100%"></div></div> <div class="bar-label"><span>R-SWA — bounded by L<sub>m</sub> + n</span><b id="swaBarTxt">2,176</b></div> <div class="bar-track"><div class="bar-fill swa" id="swaBar" style="width:21%"></div></div> <div class="formula" id="fMha">C<sub>MHA</sub>(T) = L<sub>m</sub> + T = <b id="fMhaN">2,048 + 8,000 = 10,048</b></div> <div class="formula" id="fSwa">C<sub>R-SWA</sub>(T) = L<sub>m</sub> + min(n, T) = <b id="fSwaN">2,048 + 128 = 2,176</b></div> </div> <div class="stream-wrap"> <div class="stream-title">Attention view: each new token sees <b>all reference tokens</b> plus only the <b>last n output tokens</b>. Earlier output is evicted from the cache.</div> <div class="stream" id="stream"></div> <div class="legend"> <span><i class="dot" style="background:#b0b0b0"></i> Reference tokens (visual + prompt, always visible)</span> <span><i class="dot" style="background:#ffffff"></i> Active window (last n tokens)</span> <span><i class="dot" style="background:#1c1c1c"></i> Evicted output (soft-forgotten)</span> </div> </div> <p class="note">Grounding: Unlimited OCR keeps the full reference cache of size L<sub>m</sub> but holds only the most recent n output tokens (n defaults to 128). As output length T grows far beyond n, the cache ratio ρ(T) trends toward zero, so MHA's linear growth is replaced by a constant footprint. The page-to-token estimate uses the DeepEncoder figure of 256 tokens per 1024×1024 page. Numbers illustrate the cache formulas in the report, not a benchmark run.</p> <div class="foot"> <span>R-SWA cache formulas from the Unlimited OCR technical report (arXiv:2606.23050)</span> <span>Built by <b>Marktechpost</b></span> </div> </div> <script> (function(){ var pages=document.getElementById('pages'), tokens=document.getElementById('tokens'), win=document.getElementById('window'); var TOK_PER_PAGE=256; var anim=null; function fmt(n){return Math.round(n).toLocaleString('en-US');} function render(){ var P=+pages.value, T=+tokens.value, n=+win.value; var Lm=P*TOK_PER_PAGE; var mha=Lm+T; var swa=Lm+Math.min(n,T); var ratio=swa/mha; var saved=Math.round((1-ratio)*100); document.getElementById('pagesVal').textContent=P+(P===1?' page':' pages'); document.getElementById('tVal').textContent=fmt(T); document.getElementById('nVal').textContent=n; document.getElementById('mhaVal').textContent=fmt(mha); document.getElementById('swaVal').textContent=fmt(swa); document.getElementById('ratioVal').textContent=ratio.toFixed(3); document.getElementById('saveVal').textContent=saved+'%'; var maxC=mha; document.getElementById('mhaBar').style.width='100%'; document.getElementById('swaBar').style.width=Math.max(2,(swa/maxC)*100)+'%'; document.getElementById('mhaBarTxt').textContent=fmt(mha); document.getElementById('swaBarTxt').textContent=fmt(swa); document.getElementById('fMhaN').textContent=fmt(Lm)+' + '+fmt(T)+' = '+fmt(mha); document.getElementById('fSwaN').textContent=fmt(Lm)+' + '+fmt(Math.min(n,T))+' = '+fmt(swa); drawStream(T,n); postHeight(); } function drawStream(T,n){ var s=document.getElementById('stream'); s.innerHTML=''; var REF=10, OUT=34; for(var i=0;i<REF;i++){ var r=document.createElement('div'); r.className='tok ref'; s.appendChild(r); } var prog=Math.min(1, T/120000); var generated=Math.round(prog*OUT); var winCells=Math.max(1,Math.round((n/512)*8)); for(var j=0;j<OUT;j++){
Related
相關文章

OpenAI 再次升級 GPT-5.5 Instant AI:更具洞察力,購物推薦更實用
這篇消息聚焦「OpenAI 再次升級 GPT-5.5 Instant AI:更具洞察力,購物推薦更實用」。原始導語提到:OpenAI 今天(6 月 25 日)在 X 平臺發佈公告,宣佈升級 GPT-5.5 Instant 模型,更能洞察用戶表達意圖,並在處理複雜任務時更可靠。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。
正確使用微信“小微”的12個姿勢
AI應用風向標(公眾號:ZhidxcomAI) 作者|江宇 編輯|漠影 聊天記錄太多?你的“小微”來了! 智東西6月24日報道,近日,微信原生AI助手“小微”正在開啟灰度測試。 ▲微信原生AI助手“小微”主頁面 智東西第一時間拿到內測資格,高強度體驗一天後,我們發現:小微幾乎出現在了微信裡的每一個信息消費場景。 一對一聊天消息可以問小微,群聊可以問小微;公眾號文章可以問小微,視頻號可以問小微;圖片、PDF、TXT、Word、PPT、Excel,同樣也能問小微。 順著這些入口一路往下挖,我們最終在微信裡找到了12個“小微”入口。 對於很多用戶來說,每天花在微信裡的時間,並不僅僅只是聊天。朋友圈、公眾號、群消息、文件等內容散落各處,過去需要自己搜索整理。 現在,小微正在嘗試成為這些信息入口之間的新中介。 這也構成了它與市面上主流Chatbot的最大差異:Chatbot是在聊天框裡擴展高頻應用場景;而微信的思路,是把AI自然地融入原有的高頻場景中。 再來看小微背後的模型能力。其主模型為微信團隊自研的WeLM(a Well-read Pre-trained Language Model),部分回答會結合DeepSeek完成。從體驗上看,小微單獨做通用問答並非獨特,但它能真正調動微信生態內的信息和原生功能。 這直接解決了一個痛點:對於擁有大量好友、聊天記錄繁雜的重度微信用戶來說,查找散落在聊天記錄中的信息,一直是一個特別大的剛需。現在,不僅聊天記錄有了智能檢索,就連藏在“文件傳輸助手”中的寶藏,也都能被挖掘出來了。 為了實現這種無縫的“挖寶”與交互體驗,微信將小微巧妙地編織進了各個功能區。目前,我們找到的12個入口,可以歸納為四類: 第一類是獨立入口,也就是微信首頁左上角那雙綠色眼睛; 第二類是嵌入聊天界面的入口,包括通過聊天消息長按、點對點聊天右下角“+”號,以及群聊右下角“+”號
加持文心5.1底座:百度文心網站全面擴容,Office在線編輯等工具上新
百度宣布將旗下文心相關網站整合為全新「百度文心網站」,打造一站式AI服務入口,技術基底已升級為文心5.1大模型。此次擴容同時新增Office在線編輯等工具,旨在降低用戶使用門檻並提升效率。
馬斯克悄悄改了戰場:Grok Build 0.2.60 劍指 Agent Runtime
Grok Build CLI:一次不炫技、但很關鍵的更新。 作者丨樊天驕、鄭佳美 編輯丨鄭佳美 2026 年 6 月 21 日,Grok Build 悄悄發佈了 0.2.60 版本更新。消息最早由 X 平臺技術博主 Mark Kretschmann 披露。與常見的大版本發佈不同,這次更新既沒有推出新的模型能力,也沒有刷新任何 Benchmark,而是將重心放在會話恢復、上下文壓縮、MCP 工具輸出等一系列 Runtime 細節上。這些改動或許不如模型升級那樣引人注目,卻恰恰指向了 AI 編程工具競爭的新焦點。因為當模型能力逐漸趨同時,真正決定 Agent 體驗的往往不再是它有多聰明,而是它能否穩定、持續地完成工作。而要理解這種變化為何重要,就需要先回顧 AI 編程工具競爭重心是如何一步步發生遷移的。Coding Agent 的發展歷程總結來說分為三個階段。早期開發者的研究重心放在其寫代碼的能力上,大家更多關注的是 AI 是否能補全代碼和生成函數。隨後階段大家的關注點則轉向它是否可以獨自完成工作流,如理解項目結構的,完成跨文件修改,並跑通測試。到了 Agent 階段,開發者真正考驗的是系統能否長時間穩定接活:在多個倉庫之間正確恢復上下文,在任務執行過程中保持可控,在調用外部工具後不被海量日誌和結果拖垮,並能在半自動化甚至無人值守場景中持續運行。Grok Build 正是在這個背景下出現的。它不是一個單純的聊天式編程助手,而是運行在終端中的 Coding Agent,目標是參與真實且完整的軟件工程流程:理解倉庫、制定計劃、調用工具、修改文件、運行命令、等待用戶確認,再繼續推進任務。xAI 官方資料顯示,Grok Build 支持交互式使用、腳本化運行、外部工具接入和多會話管理,這意味著 Grok Build 0.2.60 的價值並不在於讓代碼生成看起來更漂亮,而在於能不能把一個
中國存儲,世界第一!這次不是實驗室跑分
智東西 作者 | 李水青 編輯 | 心緣 智東西6月25日報道,6月24日,ISC 2026大會傳來消息:中科曙光ParaStor F9000全閃存儲系統同時登頂IO500生產型全節點和10節點雙榜第一,成為首個拿下這項雙料冠軍的中國廠商。 這是中國存儲產業的歷史性時刻。過去,IO500生產型榜首長期被國際巨頭壟斷,國產存儲首次站上了這個最嚴苛賽道的最高領獎臺。 ▲IO500 生產型全節點第一 ▲IO500 生產型10節點第一 過去很長時間裡,存儲只是算力敘事中的配角。當AI訓練進入PB級吞吐時代,瓶頸從芯片轉向了數據供給:GPU空轉、訓練中斷、checkpoint恢復耗時數小時,根因都指向存儲。存儲,已成為決定GPU利用率的勝負手。 行業早已告別了只看紙面參數的時代。中國廠商此次登頂的IO500生產型榜單,堪稱存儲實戰能力的試金石,它只認真實業務負載,中科曙光ParaStor F9000已在數萬卡集群中穩定運行超過一年,穩定支撐上百個AI、科學計算應用。可以說,這次登頂是一次benchmark(基準測試)被真實業務“跑成了生產標準”的驗證。 一、Benchmark迎來新拐點:存儲不能只拼實驗室成績 benchmark為何如此重要? 在超算與AI基礎設施領域,IO500已成為全球高性能存儲系統最具權威性的評測基準,與定義算力的TOP500榜單共同構成了衡量超算產業實力的兩大風向標。長期以來,包括英特爾、DDN等國際巨頭,都將IO500視為展示技術實力的最高舞臺。 其中,生產型榜單的要求極為嚴苛。該榜單僅納入已在真實生產環境中長期運行的存儲系統,要求滿足實際業務負載、冗餘設計與持續運行能力,部署週期通常以年計算。 中國存儲行業過去不缺實驗室冠軍,缺的是能在生產環境扛旗的選手。 ParaStor F9000此次用雙重驗證改變了這一局面: 第一重驗證來自IO500測試本身。IO5
AI懂你所想:OpenAI 升級 GPT-5.5 Instant,購物推薦更“聰明”
OpenAI於6月25日推出輕量模型GPT-5.5 Instant新版,核心升級聚焦提升“洞察力”與任務執行穩定性,使AI更精準把握用戶意圖。自5月首發以來,該模型在醫學、金融及法律等高風險領域幻覺率已大幅降低52.5%,數理推理能力突出。本次迭代則在此基礎上再進一步,強化專業場景下的可靠表現。