認識 Harness-1:基於 gpt-oss-20b,在狀態化搜尋框架內以強化學習訓練的 200 億參數檢索子代理
重點摘要
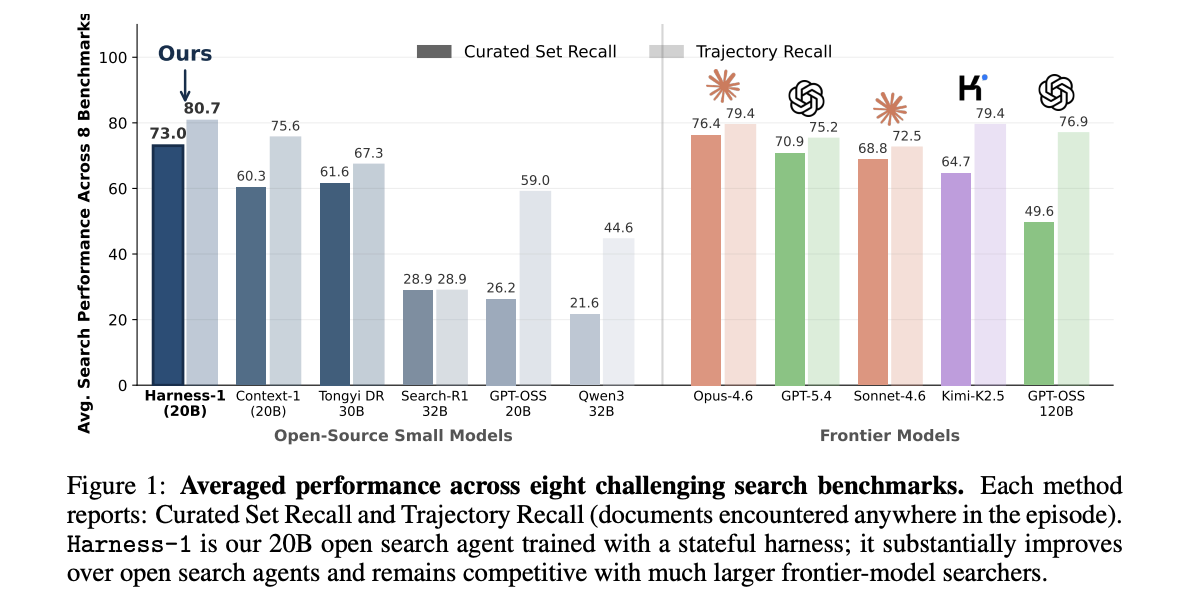
大多數搜尋代理是根據不斷增長的記錄訓練而成的策略。模型必須決定如何搜尋,同時記住所看到的內容、哪些證據重要、以及哪些主張已被驗證。來自伊利諾大學厄巴納-香檳分校、加州大學柏克萊分校及 Chroma 的研究團隊認為,這要求過高。強化學習往往同時最佳化搜尋決策與常規簿記工作。他們的解答是 Harness-1,一個基於 gpt-oss-20b 的 200 億參數檢索子代理,在狀態化搜尋框架內以強化學習訓練。該框架負責簿記,策略則保留語意決策。模型權重與框架程式碼已公開釋出。https://arxiv.org/pdf/2606.02373
Most search agents are trained as policies over a growing transcript. The model decides how to search. It must also remember what it saw, which evidence matters, and which claims it checked. A team of researchers from University of Illinois Urbana-Champaign, UC Berkeley, and Chroma argues this asks too much. Reinforcement learning ends up optimizing both search decisions and routine bookkeeping at once. Their answer is Harness-1, a 20B retrieval subagent built on gpt-oss-20b. It was trained with reinforcement learning inside a stateful search harness. The harness holds the bookkeeping. The policy keeps the semantic decisions. The weights and harness code are publicly released. https://arxiv.org/pdf/2606.02373 What is Harness-1 Actually Harness-1 produces a ranked set of documents for a downstream answering model. It does not answer questions itself. It runs inside a state-machine harness centered on a per-episode WORKINGMEMORY. Each turn works as a loop. The harness renders compact search state along with recent actions. The model emits one structured action. The harness executes it, updates state, and renders the next observation. The Stateful Harness: What Moves Out of the Policy The research team calls its principle stateful cognitive offloading. The policy decides what to search, curate, and verify, and when to stop. The harness maintains the recoverable state around those decisions. That state includes several pieces. A candidate pool holds compressed, deduplicated documents. An importance-tagged curated set is the final output, capped at 30 documents. Tags take four values: very_high, high, fair, or low. A full-text store keeps every retrieved chunk outside the prompt. An evidence graph adds structure. A regex extractor scans each chunk for proper nouns, years, and dates. The harness then renders frequent entities, bridge documents, and singletons. Bridge documents contain two or more frequent entities. Singletons appear in one document and suggest follow-up leads. The policy works through eight tools. These are fan_out_search, search_corpus, grep_corpus, read_document, review_docs, curate, verify, and end_search. Search outputs are compressed with sentence-BM25, keeping the top four sentences. Two-level deduplication removes repeats by chunk ID and content fingerprint. One design choice addresses cold starts. The first successful search auto-seeds the curated set with eight reranked results at fair importance. The policy then promotes strong documents and removes weak ones. This turns the task from building from scratch into refinement. The research team names three requirements for a trainable harness. These are warm-started curation, compact derived-state rendering, and diversity-preserving incentives. Harness-1 implements all three. How It is Trained Training splits along the same line as the harness. Supervised fine-tuning teaches the model to operate the interface. Reinforcement learning improves search decisions over the maintained state. A single teacher, GPT-5.4, runs live inside the full harness. After filtering, 899 trajectories remain for SFT. The model uses LoRA at rank 32 for three epochs. The step-550 checkpoint initializes RL. RL uses on-policy CISPO with a 40-turn cap and terminal-only reward. It trains only on SEC queries. Groups with identical rewards are dropped from the gradient. Training ran on Tinker. The reward separates discovery from selection. It also adds a tool-diversity bonus. Without that bonus, the agent collapses to repeated search. Curated recall then plateaus near 0.53. With the bonus, diversity stabilizes and recall reaches about 0.60. The Benchmark Case Harness-1 was evaluated on eight benchmarks spanning web, finance, patents, and multi-hop QA. The main metric is curated recall: coverage of relevant documents in the final set. Trajectory recall counts evidence encountered anywhere in the episode. ModelTypeAvg Curated RecallAvg Trajectory RecallHarness-1 (20B)Open small0.7300.807Tongyi DeepResearch 30BOpen small0.6160.673Context-1 (20B)Open small0.6030.756Search-R1 (32B)Open small0.2890.289GPT-OSS-20BOpen small0.2620.590Qwen3 (32B)Open small0.2160.446Opus-4.6Frontier0.7640.794GPT-5.4Frontier0.7090.752Sonnet-4.6Frontier0.6880.725Kimi-K2.5Frontier0.6470.794GPT-OSS-120BFrontier0.4960.769Averages across eight benchmarks, from Figure 1 of the paper. Frontier models run as zero-shot retrievers under the Context-1 harness. Harness-1 reaches 0.730 average curated recall. That beats the next open subagent, Tongyi DeepResearch 30B, by 11.4 points. Among the frontier searchers tested, only Opus-4.6 scores higher on average. The transfer pattern is the clearest signal of the mechanism. SFT used four benchmark families; RL used only SEC. On those source-family tasks, Harness-1 gained 7.9 points over the closest open baseline. On four held-out benchmarks, it gained 17.0 points. That is a 2.2x larger gain on tasks furthest from training data. Ablations support the harness claim. Disabling all harness mechanisms drops Recall by 12.2 percent relative on BrowseComp+. The trained policy keeps searching but cannot rank what it sees. https://arxiv.org/pdf/2606.02373 Use Cases The method targets evidence-seeking retrieval where documents support an answer. Several workflows fit this shape. One is literature and patent review. The evidence graph and curated set help organize many sources. Another is financial-filing analysis. The SEC case study recovers an exact executive-transition date across multiple 8-Ks. A third is multi-hop fact-checking. The fan_out_search and verify tools resolve ambiguous entities before committing. A fourth is modular RAG. The curated set feeds a frozen generator, and better sets yield higher answer accuracy. Strengths and Weaknesses Strengths Highest average curated recall among the open models tested, and behind only Opus-4.6 overall. Gains hold on held-out benchmarks, suggesting domain-general search operations. Trained on 4,352 unique items, far fewer than several baselines. Open checkpoint and harness code, servable with common runtimes. Weaknesses The evidence graph uses regex extraction, not full entity linking. The verify tool is an LLM proxy that can err on ambiguous claims. Sentence-BM25 compression may drop context tied to discourse structure. The research team reports point estimates without full confidence intervals. Key Takeaways Harness-1 is a 20B search agent that moves search bookkeeping into the environment, leaving semantic decisions to the policy. It hits 0.730 average curated recall across eight benchmarks, beating the next open subagent by 11.4 points. Among the searchers tested, only Opus-4.6 scores higher on average curated recall. Gains are largest on held-out benchmarks (+17.0 vs +7.9 points), suggesting the learned search operations transfer. Weights and harness code are public, servable via vLLM, SGLang, or Transformers. Marktechpost’s Visual Explainer #mtp-harness1-slider *{box-sizing:border-box!important;margin:0;padding:0} #mtp-harness1-slider hr,#mtp-harness1-slider p:empty,#mtp-harness1-slider del,#mtp-harness1-slider s{display:none!important} #mtp-harness1-slider{ --mtp-bg:#f4f6f8!important; --mtp-card:#ffffff!important; --mtp-ink:#10243a!important; --mtp-muted:#5a6b7b!important; --mtp-line:#e2e8ef!important; --mtp-accent:#0e9f6e!important; --mtp-accent-dk:#0a7d56!important; --mtp-soft:#e8f6f0!important; --mtp-chip:#eef2f6!important; background:var(--mtp-bg)!important; color:var(--mtp-ink)!important; border:1px solid var(--mtp-line)!important; border-radius:18px!important; padding:0!important; max-width:860px!important; margin:24px auto!important; font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Helvetica,sans-serif!important; line-height:1.55!important; overflow:hidden!important; box-shadow:0 10px 40px rgba(16,36,58,.08)!important; } #mtp-harness1-slider .mtp-h1-head{ display:flex!important;align-items:center;justify-content:space-between; padding:16px 24px!imp
Related
相關文章

Edge AI Daily 早報(6月19日)
AI Engineer World's Fair 2026規模再創新高,標誌AI工程從幕後走向舞臺中央。行業面臨結構性調整:楊立昆警示OpenAI年虧210億美元揭示商業模式脆弱性,Transformer之父轉投OpenAI反映人才爭奪白熱化。Anthropic多線佈局——語音支持七種語言、加入碳清除聯盟、落子首爾辦事處,展現生態擴張野心。監管壓力加劇,意大利依據DMA調查蘋果iCloud,巴西開放iOS側載佣金降至5%,蘋果圍牆花園持續崩塌。

今天起,Claude Design要把設計師和程序員變成同一種人了
猝不及防!Anthropic深夜甩出Claude Design大更新,設計系統一鍵導入,代碼雙向同步,9大平臺一鍵導出。Anthropic設計師親自下場錄屏:AI跑了八輪自查,才敢把設計稿給你看。

OpenAI 成為 Rust 基金會白金會員,合計贊助 60 萬美元
OpenAI 正式成為 Rust 基金會白金會員,將提供總計 60 萬美元資金,用於支持 Rust 開源項目維護者及 Rust 創新實驗室等計劃。這標誌著 AI 巨頭對安全、高效系統編程語言的重視。 #OpenAI #Rust #開源

Claude Design 上線首周用戶破百萬,和 Claude Code 共享 AI 配額
Anthropic 今天(6 月 18 日)發佈公告,在宣佈 Claude Design 上線首周用戶規模突破 100 萬後,進一步強化和 Claude Code 的雙向聯動,實現從設計到編程的無縫工作流。
谷歌時隔6年再發智能音箱,Gemini上桌,售價不到700元
智東西 編譯 | 劉煜 編輯 | 陳駿達 智東西6月18日消息,谷歌昨日宣佈,其首款搭載居家版Gemini語音助手的智能音箱(Google Home Speaker)已開啟預售,將於當地時間6月25日正式上市,售價為99.99美元(約合人民幣677.03元)。在此之前,谷歌已有6年沒有推出過獨立智能音箱產品。 谷歌這款智能音箱外觀近似球形,風格類似亞馬遜新一代Echo音箱與蘋果舊款音箱HomePod Mini。 ▲谷歌智能音箱(圖源:谷歌官網) 使用音箱時,用戶只需通過口令“Hey Google”或“OK Google”喚醒Gemini,就可以繼續下達相應指令。這與谷歌舊款音箱、智能顯示屏等喚醒語音助手的方式相同。此外,用戶只要按照日常說話習慣下達命令,Gemini便能理解用戶意圖,相比之前大大提升溝通效率。 一、加強短時對話記憶,會員可與Gemini不限次數對話 谷歌此次推出的全新音箱升級諸多功能。其中,音箱搭載的Gemini語音助手擁有10款全新擬人化語音音色,用戶可以根據喜好自行選擇聲線。音箱還可支持用戶一次性下達多條語音指令,即使指令未能說對、說完整,用戶中途改口Gemini也能識別。 Gemini還具備多鏈路推理能力,落地到實際生活場景中比較實用。例如,用戶問:“我支持的足球隊下場比賽天氣如何?”Gemini收到指令後,會自動查詢賽事時間、舉辦地點,同時匹配相應時段天氣,再給出答覆。 同時,Gemini加強了短時對話記憶,能承接上下文實現連續對話功能。即使用戶連續追問、甚至串聯多項任務、不重複交代前置條件,該語音助手也能實現來回連貫交流。 ▲谷歌Gemini對話場景(圖源:谷歌官網) 不僅如此,Gemini搭配的連續對話功能,能讓應答後的音箱麥克風保持短暫收音,用戶無需重複喊“OK Google”就能繼續提問。該功能現已全面支持所有Gemini原生適配的語言,包括

微軟,考慮接入DeepSeek
這篇消息聚焦「微軟,考慮接入DeepSeek」。原始導語提到:Copilot Cowork轉為按量計費。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。