MiniMax 稀疏注意力(MSA):基於 109B 參數 MoE 與 3T Token 預算訓練的雙分支區塊稀疏注意力機制
重點摘要
MiniMax 發表了 MSA(MiniMax 稀疏注意力),這是一種直接建構在分組查詢注意力(GQA)之上的稀疏注意力方法。其目標是解決一個瓶頸:長上下文下 softmax 注意力的二次方成本。MiniMax 研究團隊在一個以原生多模態資料訓練、擁有 109B 參數的混合專家模型(MoE)中測試了該方法。他們也開源了推理核心,並推出生產級模型 MiniMax-M3。什麼是 MSA?MSA 將注意力分解為兩個階段:索引分支(Index Branch)與主分支(Main Branch)。索引分支決定每個查詢應讀取哪些鍵值區塊,主分支則僅對這些區塊執行精確的 softmax 注意力。選擇是以區塊為粒度進行,而非逐 token。預設區塊大小為 Bk = 128 個 token。
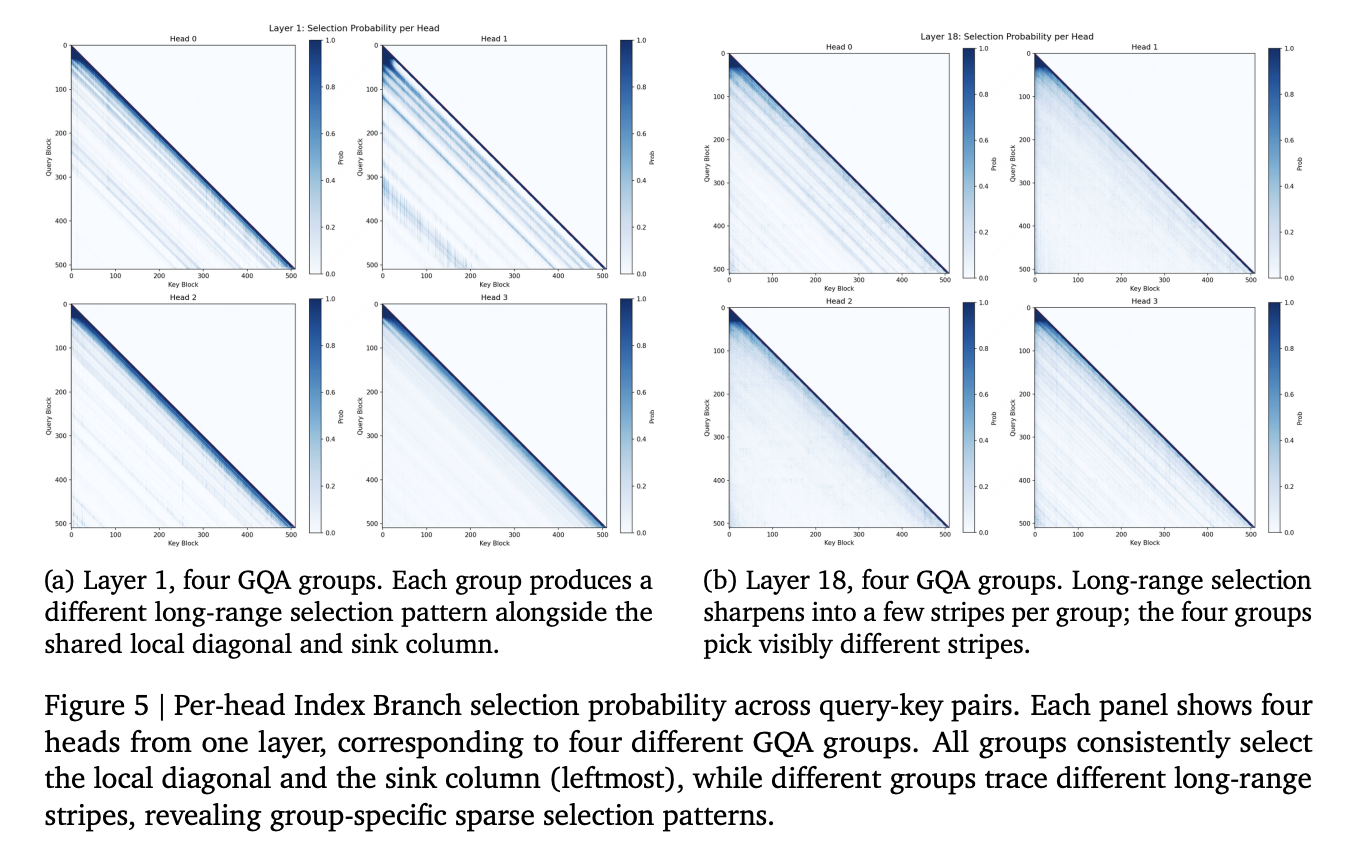
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one bottleneck: the quadratic cost of softmax attention at long context. The MiniMax research team tested it inside a 109B-parameter Mixture-of-Experts model trained with native multimodal data. They also open-sourced an inference kernel and shipped a production model, MiniMax-M3. What is MSA (MiniMax Sparse Attention) MSA (MiniMax Sparse Attention) factors attention into two stages: an Index Branch and a Main Branch. The Index Branch decides which key-value blocks each query should read. The Main Branch then runs exact softmax attention over only those blocks. Selection happens at block granularity, not per token. The default block size is Bk = 128 tokens. Each query and GQA group keeps k = 16 blocks. That fixes the per-query budget at kBk = 2,048 key-value tokens. The two cost structures differ. Dense GQA attention scales per query as O(N), the full context. MSA scales as O(kBk), which stays fixed as N grows. The compute gap therefore widens as context length increases. Selection is shared inside each GQA group but independent across groups. One key-value head serves several query heads, and they share one block set. Different groups can attend to different long-range regions. How the Two Branches Work The Index Branch adds only two projection matrices to a standard GQA layer. It defines one index query head per GQA group and one shared index key head. It scores visible key tokens, then max-pools those scores to the block level. A Top-k operator then selects the highest-scoring blocks per query and group. The local block containing the query is always included. This prevents the selector from dropping the query’s immediate neighborhood. The Main Branch gathers causally visible tokens from the selected blocks. It applies scaled dot-product softmax attention restricted to those tokens. Each query head keeps its own query projection but shares the group’s block set. A visualization in the report shows what the learned indexer selects. Heads concentrate on the local diagonal and the first block. They reserve the rest of the budget for a few long-range stripes. https://arxiv.org/pdf/2606.13392v1 https://arxiv.org/pdf/2606.13392v1 How MSA is Trained Top-k selection is non-differentiable, so the language-modeling loss cannot train the index projections. MSA solves this with a KL alignment loss. The loss matches the Index Branch distribution to the Main Branch attention pattern. The teacher is the group-averaged Main Branch distribution over the selected tokens. Three mechanisms stabilize sparse training. Gradient Detach applies stop-gradient to the Index Branch input. This confines the KL loss to the index projections, not the backbone. Without it, larger KL coefficients caused gradient spikes and loss divergence. Indexer Warmup runs full attention in both branches for the first iterations. The indexer learns from the KL loss before it controls routing. The forced Local Block reserves one slot for nearby context. Ablations shaped the final recipe. An early variant added an Index Branch value head with its own output. Once warmup is used, that value head is no longer necessary. The final design drops it on efficiency grounds. MSA supports two training routes. MSA-PT trains from scratch after a 40B-token indexer warmup. MSA-CPT converts a dense GQA checkpoint trained on 2.6T tokens. It then continues for 400B tokens, including 40B tokens of warmup. The Kernel Co-Design Theoretical sparsity does not become speed without a matching GPU path. MSA pairs the algorithm with two kernel ideas. The first is exp-free Top-k selection. Softmax preserves order, so ranking raw scores yields identical indices. The kernel skips the max, exp, and sum steps before selection. At 128K context with k = 16, it ran 5.1× faster than torch.topk. It also beat the TileLang radix-select kernel by 3.7×. The second is KV-outer sparse attention with query gather. Iterating over KV blocks raises arithmetic intensity versus iterating over queries. The kernel packs ⌈128/G⌉ query positions into one 128×128 score MMA. A two-phase forward splits the attention and combine steps across CTAs. The open-source kernel, fmha_sm100, targets NVIDIA SM100 GPUs. It ships dense FlashAttention plus sparse Top-k kernels under an MIT license. It supports BF16, FP8, NVFP4, and FP4 precision. How MSA Compares To Other Sparse Methods The research team positions MSA against four natively trained sparse designs. The table below summarizes the differences it describes. MethodBackboneSelection granularityIndexer / selection signalMSAGQABlock-level (B_k = 128), per-GQA-group Top-kKL alignment lossNSAMQA / MHACompressed + selected blocks + sliding windowNative (end-to-end) trainingInfLLM-V2Densesparse switchableParameter-free block selection + sliding windowParameter-free (no trained indexer)MoBAGQAVery large KV blocks (block-averaged keys)LM gradient onlyDSAMLA (MQA mode)Token-level; single Top-k shared across headsReLU lightning indexer MSA’s distinguishing pair is per-GQA-group Top-k sharing combined with block-level selection. This keeps KV reads contiguous while giving each group its own retrieval. The quality side holds up. Both sparse models stay broadly competitive with the Full-Attention baseline. The table below shows representative results under the 3T-token budget. BenchmarkFullMSA-PTMSA-CPTMMLU67.067.266.8GSM8K76.277.773.7HumanEval61.064.057.9RULER-8K79.884.277.2RULER-32K75.077.575.7VideoMME41.1145.4839.65 After long-context extension, MSA-CPT stayed close to Full on HELMET-128K and RULER-128K. Each query still attends to only 2,048 key-value tokens. Explainer Playground (function(){ window.addEventListener("message", function(e){ if(e && e.data && e.data.msaDemoHeight){ var f = document.getElementById("msa-demo-frame"); if(f){ f.style.height = e.data.msaDemoHeight + "px"; } } }); })(); Use Cases With Examples MSA targets workloads where context length is the binding deployment constraint. Long-horizon agents: An agent that spans hundreds of reasoning and action steps accumulates a large transcript. Dense attention over that history grows quadratically. MSA holds the per-query budget at 2,048 tokens regardless of length. Repository-scale code reasoning: A coding agent loading a full repository can exceed hundreds of thousands of tokens. The indexer routes each query to the few relevant blocks. Irrelevant files stay outside the selected set. Persistent memory: A long-running assistant keeps growing conversational state. MSA reads a fixed-size slice of the most relevant blocks per query. The decoding cost stays roughly flat as memory grows. Long video understanding: The model is natively multimodal and trained on image and video data. MSA-PT scored highest of the three runs on several video benchmarks, including VideoMME and TemporalBench. Sparse selection scales to long visual token sequences. Running the Kernel The fastest path uses the Hugging Face kernels library. Copy CodeCopiedUse a different Browser# pip install -U kernels from kernels import get_kernel kernel_module = get_kernel("MiniMaxAI/msa", version=0) sparse_atten_func = kernel_module.sparse_atten_func sparse_atten_func(...) The repository also showcases the planner, indexer, and attention call directly. Copy CodeCopiedUse a different Browserimport torch from fmha_sm100 import fmha_sm100, fmha_sm100_plan, sparse_topk_select page_size, topk = 128, 16 # Dense proxy pass: per-block max score from a cheap Q slice. proxy_plan = fmha_sm100_plan( qo_lens, kv_lens, proxy_q.shape[1], num_kv_heads=1, page_size=page_size, output_maxscore=True, ) _, max_score = fmha_sm100( proxy_q, proxy_k_pages, proxy_v_pages, proxy_plan, kv_indices=kv_indices, output_o=False, output_maxscore=True, ) # Block scores -> selected KV block indexes. kv_block_indexes = sparse_topk_select( max_score.contiguous(), topk, num_valid_pages=num_page
Related
相關文章

Edge AI Daily 早報(6月19日)
AI Engineer World's Fair 2026規模再創新高,標誌AI工程從幕後走向舞臺中央。行業面臨結構性調整:楊立昆警示OpenAI年虧210億美元揭示商業模式脆弱性,Transformer之父轉投OpenAI反映人才爭奪白熱化。Anthropic多線佈局——語音支持七種語言、加入碳清除聯盟、落子首爾辦事處,展現生態擴張野心。監管壓力加劇,意大利依據DMA調查蘋果iCloud,巴西開放iOS側載佣金降至5%,蘋果圍牆花園持續崩塌。

今天起,Claude Design要把設計師和程序員變成同一種人了
猝不及防!Anthropic深夜甩出Claude Design大更新,設計系統一鍵導入,代碼雙向同步,9大平臺一鍵導出。Anthropic設計師親自下場錄屏:AI跑了八輪自查,才敢把設計稿給你看。

OpenAI 成為 Rust 基金會白金會員,合計贊助 60 萬美元
OpenAI 正式成為 Rust 基金會白金會員,將提供總計 60 萬美元資金,用於支持 Rust 開源項目維護者及 Rust 創新實驗室等計劃。這標誌著 AI 巨頭對安全、高效系統編程語言的重視。 #OpenAI #Rust #開源

Claude Design 上線首周用戶破百萬,和 Claude Code 共享 AI 配額
Anthropic 今天(6 月 18 日)發佈公告,在宣佈 Claude Design 上線首周用戶規模突破 100 萬後,進一步強化和 Claude Code 的雙向聯動,實現從設計到編程的無縫工作流。
谷歌時隔6年再發智能音箱,Gemini上桌,售價不到700元
智東西 編譯 | 劉煜 編輯 | 陳駿達 智東西6月18日消息,谷歌昨日宣佈,其首款搭載居家版Gemini語音助手的智能音箱(Google Home Speaker)已開啟預售,將於當地時間6月25日正式上市,售價為99.99美元(約合人民幣677.03元)。在此之前,谷歌已有6年沒有推出過獨立智能音箱產品。 谷歌這款智能音箱外觀近似球形,風格類似亞馬遜新一代Echo音箱與蘋果舊款音箱HomePod Mini。 ▲谷歌智能音箱(圖源:谷歌官網) 使用音箱時,用戶只需通過口令“Hey Google”或“OK Google”喚醒Gemini,就可以繼續下達相應指令。這與谷歌舊款音箱、智能顯示屏等喚醒語音助手的方式相同。此外,用戶只要按照日常說話習慣下達命令,Gemini便能理解用戶意圖,相比之前大大提升溝通效率。 一、加強短時對話記憶,會員可與Gemini不限次數對話 谷歌此次推出的全新音箱升級諸多功能。其中,音箱搭載的Gemini語音助手擁有10款全新擬人化語音音色,用戶可以根據喜好自行選擇聲線。音箱還可支持用戶一次性下達多條語音指令,即使指令未能說對、說完整,用戶中途改口Gemini也能識別。 Gemini還具備多鏈路推理能力,落地到實際生活場景中比較實用。例如,用戶問:“我支持的足球隊下場比賽天氣如何?”Gemini收到指令後,會自動查詢賽事時間、舉辦地點,同時匹配相應時段天氣,再給出答覆。 同時,Gemini加強了短時對話記憶,能承接上下文實現連續對話功能。即使用戶連續追問、甚至串聯多項任務、不重複交代前置條件,該語音助手也能實現來回連貫交流。 ▲谷歌Gemini對話場景(圖源:谷歌官網) 不僅如此,Gemini搭配的連續對話功能,能讓應答後的音箱麥克風保持短暫收音,用戶無需重複喊“OK Google”就能繼續提問。該功能現已全面支持所有Gemini原生適配的語言,包括

微軟,考慮接入DeepSeek
這篇消息聚焦「微軟,考慮接入DeepSeek」。原始導語提到:Copilot Cowork轉為按量計費。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。