NVIDIA AI 推出 SpatialClaw:無需訓練的代理程式,將程式碼視為空間推理的動作介面
重點摘要
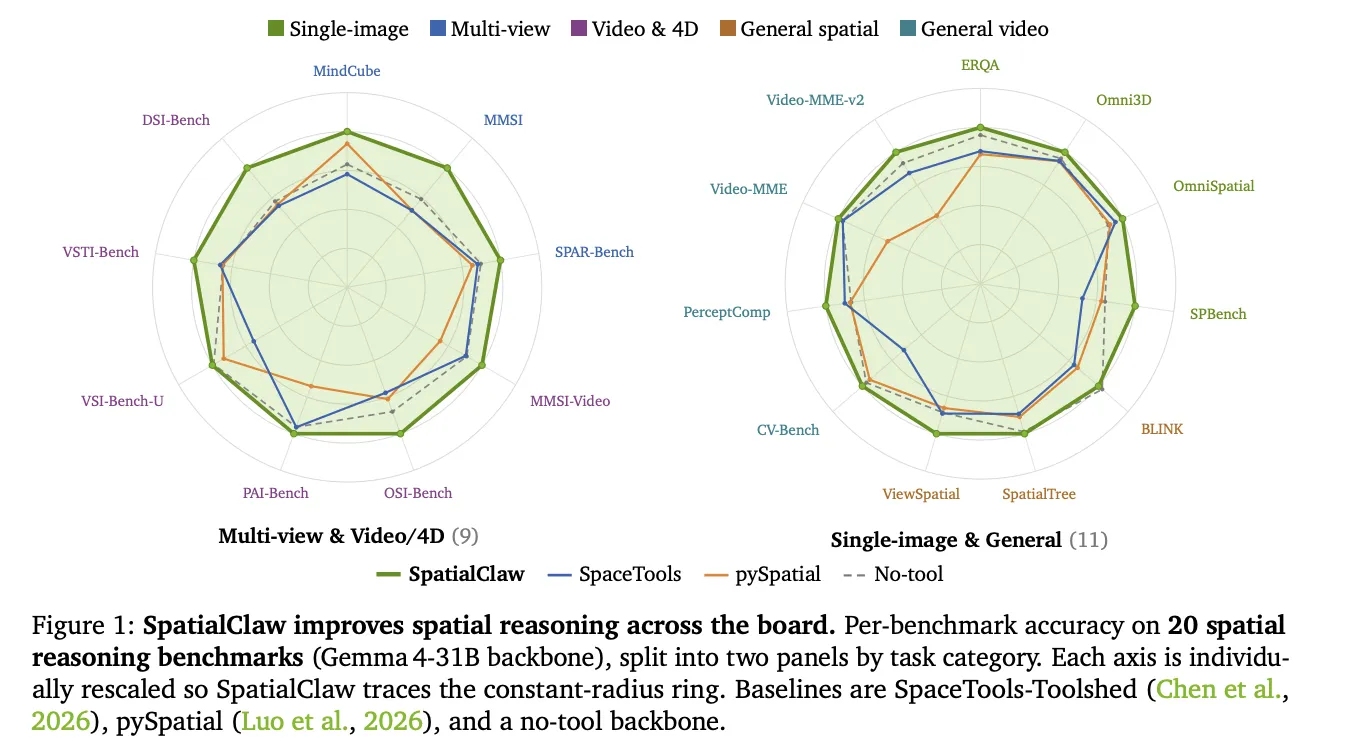
NVIDIA Research 發布了 SpatialClaw,這是一個無需訓練的空間推理框架。該框架針對視覺語言模型(VLM)持續存在的弱點——難以判斷物體的位置、相對關係及在三維空間中的移動方式。SpatialClaw 不重新訓練模型,而是改變代理程式用來呼叫感知工具的動作介面。研究團隊指出,介面才是瓶頸所在。他們的解決方案是將程式碼作為動作介面。在 20 項基準測試中,SpatialClaw 達到平均 59.9% 的準確率,比近期發布的空間代理 SpaceTools 高出 11.2 個百分點。
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). These models still struggle to judge where objects are, how they relate, and how they move in 3D. SpatialClaw does not retrain the model. Instead, it changes the action interface the agent uses to call perception tools. The research team argues the interface is the bottleneck. Their solution is to treat code as the action interface. Across 20 benchmarks, SpatialClaw reaches 59.9% average accuracy. It outperforms the recent spatial agent SpaceTools by 11.2 points. What is SpatialClaw SpatialClaw is an agent loop wrapped around a stateful Python kernel. The kernel is pre-loaded with input frames and a set of primitives. Perception tools are plain Python callables. Their outputs, including masks, depth maps, camera geometry, and trajectories, are ordinary Python variables. The kernel exposes six public entry points. InputImages holds the sampled frames. Metadata carries frame rate, duration, and frame indices. tools exposes perception and geometry primitives. show() embeds an image into the agent’s next context. vlm dispatches queries to a separate VLM session. ReturnAnswer() submits the final answer. Two perception tools are central. tools.Reconstruct wraps Depth Anything 3 and returns per-frame depth, camera intrinsics, extrinsics, and dense point maps. tools.SAM3 wraps SAM 3 and produces image or video masks from text, point, or box prompts. The framework adds lightweight utilities: tools.Geometry, tools.Mask, tools.Time, tools.Graph, and tools.Draw. It is training-free. The same system prompt, tool set, and hyperparameters run across every benchmark and backbone. https://spatialclaw.github.io/static/pdfs/spatialclaw.pdf Why the Action Interface Matters The research team studied three action interfaces on the same question. Consider measuring the closest distance between a heater and a door. Single-pass code writes one complete program and runs it once. It commits to a full strategy before seeing any intermediate mask or depth map. A wrong assumption then propagates straight to the answer. Structured tool-call invokes named tools through a fixed JSON schema. It cannot freely combine outputs with NumPy or SciPy to express test-time computations. The closest-point operation has no pre-registered tool, so the result is wrong. SpatialClaw composes tools in code, inspects results, then revises. It first computes a centroid distance, then notices the centroid uses a median. The agent switches to scipy.spatial.KDTree to find the true closest point. It submits 0.9439 m against a 0.9 m ground truth. Benchmark SpatialClaw was tested on 20 benchmarks across five categories. These span single-image, multi-view, general, video and 4D, and general video understanding. It improves over the no-tool baseline on all six backbones tested. Backbones range from 26B to 397B parameters across the Qwen3.5/3.6 and Gemma4 families. A controlled comparison isolates the interface. All three variants share the same toolset and prompt. Only the action interface differs. Action interfaceAvg. (20 bench.)Δ vs no-toolNo-tool baseline53.4–Single-pass code55.2+1.8Structured tool-call56.7+3.3SpatialClaw (code as action)59.9+6.5 Gemma4-31B backbone, 20-benchmark average. Against prior spatial agents on the same Gemma4-31B backbone, the gap widens. MethodInterfaceAvg.Δ vs SpatialClawVADARSingle-pass40.5*−19.4pySpatialSingle-pass47.8−12.1SpaceTools-ToolshedStructured tool-call48.7−11.2SpatialClawCode as action59.9bestVADAR does not support video or multi-image inputs; only single-image benchmarks are averaged. The largest gains land on dynamic tasks. On Gemma4-31B, DSI-Bench rose +17.6 points and MindCube rose +15.3 points. These categories need chained geometric computation across frames and viewpoints. An LLM-as-judge attribution explains the wins over structured tool-call. Code composition accounts for 52.2% of them. Control flow accounts for 19.5%, and the remaining 28.3% are interface-neutral. Inside the Five-Stage Loop Each sample runs a five-stage loop: planning, code generation, code execution, feedback assembly, and answer submission. A planner drafts a strategy without seeing the images. The main agent then writes one Python cell per step. A static AST checker rejects unsafe code before execution. The loop repeats until ReturnAnswer() is called or 30 steps pass. The official repo runs on a LangGraph workflow and a persistent Jupyter kernel. Backbones serve through vLLM. Perception runs behind a FastAPI GPU service. A single quickstart runs one benchmark on one machine: Copy CodeCopiedUse a different Browsergit clone --recursive https://github.com/NVlabs/SpatialClaw.git cd SpatialClaw bash spatial_agent/scripts/setup.sh cp .env.example .env # add API keys, or self-host vLLM python -m spatial_agent.entrypoints.run \ --dataset spatial_agent/config/dataset/erqa.json \ --model spatial_agent/config/model/gemini-3-pro.json \ --concurrency 4 A representative agent cell composes perception with geometry, then revises: Copy CodeCopiedUse a different Browser# Reconstruct the scene, then segment both objects in one video pass recon = tools.Reconstruct.Reconstruct(InputImages) seg = tools.SAM3.segment_video_by_text(["radiator heater", "door"]) show(seg.visualize(1)) # inspect the masks first # Closest-point distance via KD-tree, not centroids pts_h = seg.get_masked_points(recon, frame=1, object=0) # object 0 = heater pts_d = seg.get_masked_points(recon, frame=2, object=1) # object 1 = door dists, _ = scipy.spatial.KDTree(pts_d).query(pts_h, k=1) ReturnAnswer(float(dists.min())) The agent picks primitives from the question itself. Distance questions invoke KD-tree search and vector norms. Direction questions rely on dot products. No category-specific routing was applied. Use Cases The design fits problems that need step-by-step geometric reasoning. Concrete examples include: Robotics and embodied agents that measure metric distances between objects before acting. Multi-view inspection, where an object’s facing direction is recovered from several camera angles. Video and 4D analysis that tracks object or camera motion across frames. Indoor scene question answering, such as “where is the door relative to the sink?” Because it is training-free, teams can extend a deployed VLM without new data or fine-tuning. Interactive Explainer Back</button> <button class="c primary" id="sc-next">Run next step <img src="https://s.w.org/images/core/emoji/17.0.2/72x72/25b6.png" alt="▶" class="wp-smiley" style="height: 1em; max-height: 1em;" /></button> <button class="c" id="sc-reset">Reset</button> <span class="prog" id="sc-prog"></span> </div> <div class="foot"> <span>Faithful to the paper's walkthrough · interface logic is illustrative</span> <span>Built for <b>Marktechpost</b> · verified Jun 2026</span> </div> </div> <script> (function(){ var root=document.getElementById('sc-root'); if(!root)return; var $=function(s){return root.querySelector(s)}; // --- step data, faithful to Figure 2 of the SpatialClaw paper --- var DATA={ single:{ label:"single-pass · no persistence", stateNote:"No intermediate state. One complete program is committed before any execution feedback is seen.", vars:[], steps:[{ think:"Write one complete program now, before seeing any mask, depth map, or error.", code:'<span class="cm"># commit the full analysis up front</span>\nrecon = tools.<span class="fn">Reconstruct</span>(frames_for_recon)\nseg_heater = tools.<span class="fn">SAM3</span>(img_heater, <span class="st">"white radiator heater"</span>)\nimg_door = InputImages[2]\n<s
Related
相關文章
網易有道全面向AI轉型 全場景Agent矩陣亮相圖博會
{"id":"39ef5947-b77a-4904-bf03-ff6264f08dc4","object":"response","model":"deepseek-v4-flash","output":[],"stop_reason":"max_output_tokens","usage":{"input_tokens":154,"output_tokens":200,"total_tokens":354}}
MosaicLeaks: Can your research agent keep a secret?
Back to Articles MosaicLeaks: Can your research agent keep a secret? Enterprise Article Published June 18, 2026 Upvote - Alexander Gurung agurung Follow ServiceNow Rafael Pardinas rafapi-snow Follow ServiceNow TL;DR Deep research agents increasingly combine private local documents with external tools like web retrieval, creating a privacy risk: an agent's external queries may leak sensitive information. MosaicLeaks proposes a new deep-research task with multi-hop questions that interleave public and private information. Across the models we tested, agents frequently leaked private information, and training only for task performance made it worse. We propose a mosaic-leakage-aware RL training method, Privacy-Aware Deep Research (PA-DR), which raises strict chain success (the share of chains

騰訊老兵+大廠00後新銳,碼上飛想做的不只是AI Coding
這篇消息聚焦「騰訊老兵+大廠00後新銳,碼上飛想做的不只是AI Coding」。原始導語提到:已接入華為鴻蒙生態 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

Agent引爆網盤大戰,騰訊、百度、阿里齊聚,這次爭的不再是下載速度
這篇消息聚焦「Agent引爆網盤大戰,騰訊、百度、阿里齊聚,這次爭的不再是下載速度」。原始導語提到:網盤成了Agent新基建。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。
21年老牌企服公司的AI實驗:讓Agent跑一遍流程
這篇消息聚焦「21年老牌企服公司的AI實驗:讓Agent跑一遍流程」。原始導語提到:司盟企服接入騰訊雲WorkBuddy後,將海外郵件管理、審計理賬、訂單審核等高頻交付流程交給Agent先跑一遍 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。
曹操出行宣佈啟動全面AI轉型,組織升級向AI原生公司邁進
曹操出行在2026國際汽車及供應鏈博覽會 上宣佈啟動全面AI轉型,併發布RoboX戰略,打造全球領先的物理AI移動科技平臺。與此同時,公司正式啟動組織升級,加快向AI原生公司邁進。為推動全面AI轉型,今年上半年,公司推進戰略聚焦,持續優化業務結構,主動收縮非核心業務,加快向AI原生公司轉型。