NVIDIA 發表 Nemotron 3.5 ASR:6 億參數的快取感知串流模型,即時轉錄 40 種語言區域
重點摘要
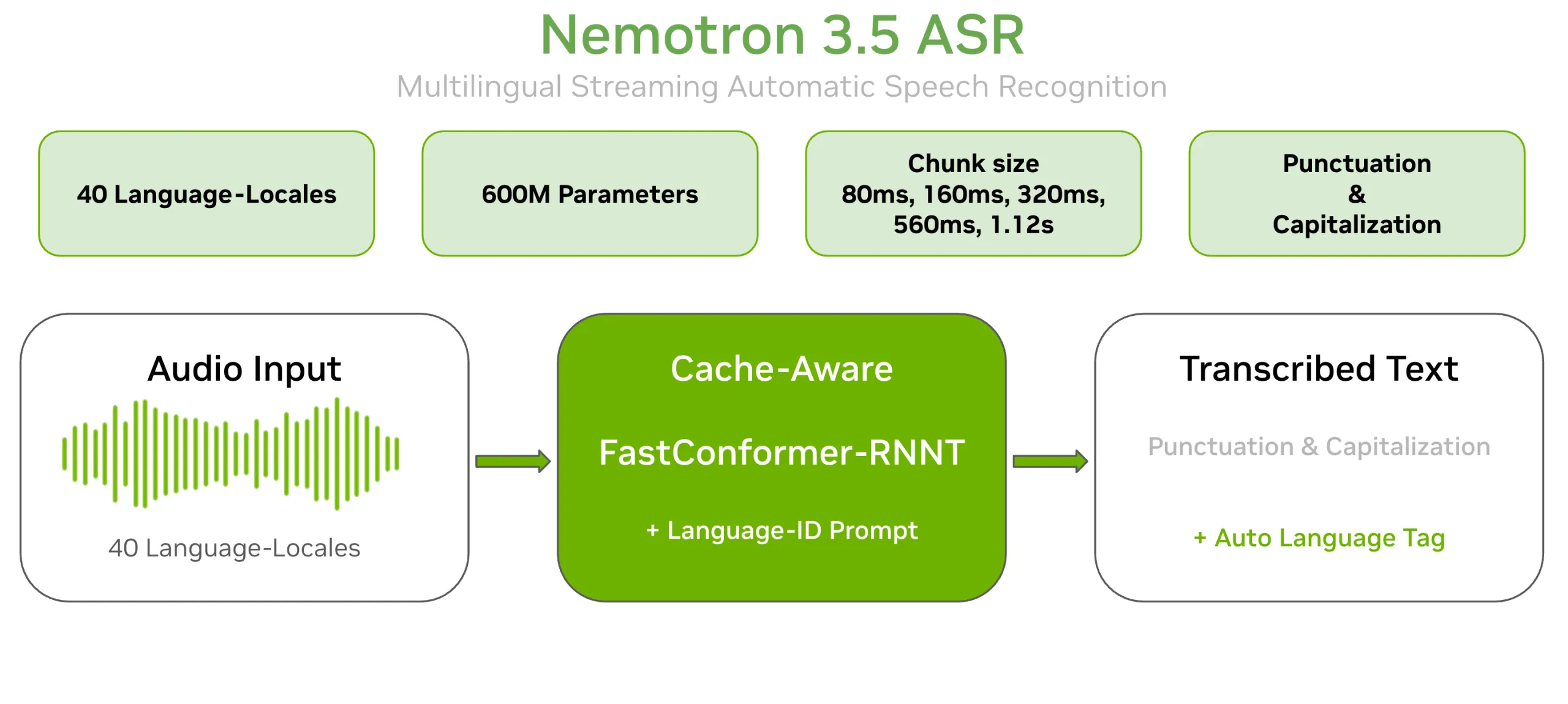
NVIDIA 的 Nemotron 語音團隊推出 Nemotron 3.5 ASR。這是一款具備 6 億參數的串流式自動語音辨識(ASR)模型,單一檢查點即可即時轉錄 40 種語言區域,並原生支援標點符號與大小寫。模型以開放權重形式發佈於 Hugging Face,採用 OpenMDW-1.1 授權,其架構為快取感知的 FastConformer-RNNT。Nemotron 3.5 ASR 將 nvidia/nemotron-speech-streaming-en-0.6b 擴展至多種語言,在基礎模型中加入基於提示的語言 ID 條件,讓一個 6 億參數的檢查點即可涵蓋 40 種語言區域,無需針對各語言建立獨立模型或進行模型切換。此模型針對兩種工作負載設計:一是適用於即時音訊的低延遲串流,二是高吞吐量的批次處理。
NVIDIA’s Nemotron Speech team has released Nemotron 3.5 ASR. It is a 600M-parameter streaming Automatic Speech Recognition (ASR) model. A single checkpoint transcribes 40 language-locales in real time. Punctuation and capitalization are built in natively. The model ships as open weights on Hugging Face. The license is OpenMDW-1.1. The architecture is a Cache-Aware FastConformer-RNNT. What is Nemotron 3.5 ASR Nemotron 3.5 ASR extends nvidia/nemotron-speech-streaming-en-0.6b to many languages. It adds prompt-based language-ID conditioning to the base model. That lets one 600M-parameter checkpoint cover 40 language-locales. No per-language model or model-swapping is required. The model targets two workloads. The first is low-latency streaming for live audio. The second is high-throughput batch transcription. Output is production-ready text with proper casing and punctuation. No separate punctuation-restoration step is needed. Image source: https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b How Cache-Aware FastConformer-RNNT Works The model has two main pieces. The first is a Cache-Aware FastConformer encoder with 24 layers. FastConformer is an efficient evolution of the Conformer architecture. It uses linearly scalable attention. The second piece is an RNNT (Recurrent Neural Network Transducer) decoder. RNNT emits text frame by frame as audio streams in. The “cache-aware” design is the efficiency lever. Buffered streaming re-processes overlapping audio windows at every step. That repeats the same work and adds delay. This model caches encoder self-attention and convolution activations instead. It reuses those cached states as new audio arrives. So each audio frame is processed exactly once, with no overlap. Compute and end-to-end latency both drop, without an accuracy penalty. The Latency Knob: att_context_size One inference setting controls the latency-accuracy tradeoff. It is the attention context size, att_context_size. Smaller context emits text sooner but sees less future audio. Larger context raises accuracy at higher latency. The same checkpoint covers the full range. Settings map to chunk sizes of 80ms, 160ms, 320ms, 560ms, and 1.12s. For example, [56,0] gives an 80ms ultra-low-latency mode. The [56,13] setting gives 1.12s for highest accuracy. Teams pick the operating point at inference time, with no retraining. Language Detection and Coverage The 40 language-locales include English, Spanish, German, and French variants. They also cover Arabic, Japanese, Korean, Mandarin, Hindi, and Thai. Several other European and Nordic languages are included too. Language conditioning works two ways. Setting target_lang to a known locale usually gives the best accuracy. Setting target_lang=auto lets the model detect the language itself. In auto mode, it emits a language tag after terminal punctuation. One deployment can then transcribe mixed-language traffic. No separate language-ID component is required. Comparison ProductCompanyAccessNative streamingLanguage coverageReported latencyPricing modelNemotron 3.5 ASRNVIDIAOpen weights (OpenMDW-1.1), self-host; hosted on DeepInfraYes — cache-aware FastConformer-RNNT40 language-locales80ms–1.12s, configurable at inferenceFree to self-host; usage-based via hostWhisper large-v3OpenAIOpen weights (MIT), self-host; APINo — offline/batch~99 languages Not streaming-nativeSelf-host free; API ~$0.006/min (batch) Nova-3DeepgramClosed API; on-premise/self-host (enterprise)Yes — streaming + batchMultilingual; +10 monolingual languages added Jan 2026 Low-latency streaming (reported sub-300ms)~$0.0077/min (Nova-3 Monolingual, PAYG) Universal-3 Pro StreamingAssemblyAIClosed API (EU endpoint available)Yes6 languages: English, Spanish, French, German, Italian, Portuguese Sub-300ms (official); first partial ~750ms Usage-based (PAYG)Scribe v2 RealtimeElevenLabsClosed APIYes90+ languages (99 per ElevenLabs) ~150ms (p50) ~$0.28/hour Ursa / streamingSpeechmaticsAPI + on-premise + edgeYes — streaming + batch50+ languages with automatic identification Ultra-low latency (positioned)Enterprise/usage Fine-Tuning Results Because the weights are open, teams can fine-tune for a language, domain, or accent. NVIDIA published a worked example on Greek and Bulgarian. It fine-tuned the base checkpoint with the same Cache-Aware FastConformer-RNNT recipe. Each clip carried a target_lang tag for language conditioning. Training data came from public corpora, including Granary, Common Voice, and FLEURS. Results were measured as WER on held-out FLEURS, at the 80ms setting. Greek WER fell from 35 to 24, a 32% relative improvement. Bulgarian fell from 22 to 15, a 31% relative improvement. These are raw WER percentages at the lowest-latency streaming mode. NVIDIA notes that evaluating at deployment latency, on held-out data, gives honest numbers. Strengths and Considerations Strengths: One 600M-parameter checkpoint covers 40 language-locales, cutting deployment sprawl. Cache-aware streaming processes each frame once, reported at 17x buffered concurrency on an H100. att_context_size tunes latency from 80ms to 1.12s at inference, with no retraining. Punctuation, capitalization, and auto language tagging are built in. Open weights enabled a 31–32% relative WER drop on Greek and Bulgarian after fine-tuning. Considerations: The model handles English, but NVIDIA recommends its dedicated English model for English-only use. The 80ms mode trades some accuracy for the lowest latency. Japanese and Korean use CER, so cross-language error comparisons need care. Throughput figures are measured on H100, so results on other GPUs will differ. The production NIM with gRPC streaming is announced, but not yet released. Key Takeaways NVIDIA’s Nemotron 3.5 ASR is an open-weights (OpenMDW-1.1), 600M-parameter streaming model transcribing 40 language-locales from one checkpoint. Its Cache-Aware FastConformer-RNNT design processes each audio frame once, reported at 17x the concurrent streams of buffered approaches on an H100. Latency is configurable from 80ms to 1.12s at inference via att_context_size, with no retraining. A short fine-tune cut FLEURS WER 32% on Greek (35→24) and 31% on Bulgarian (22→15), at the 80ms setting. It is self-hostable and streaming-native, unlike closed APIs (Deepgram, AssemblyAI, ElevenLabs) or offline Whisper. Marktechpost’s Visual Explainer NEMOTRON 3.5 ASR 1 / 10 NVIDIA · STREAMING SPEECH AI · OPEN WEIGHTS Nemotron 3.5 ASR A 600M-parameter cache-aware streaming model that transcribes 40 language-locales in real time, from a single checkpoint. 600M parameters 40 language-locales 80ms–1.12s latency OpenMDW-1.1 01 — WHAT IT IS One model, 40 language-locales Extends nvidia/nemotron-speech-streaming-en-0.6b with prompt-based language-ID conditioning. A single 600M-parameter checkpoint covers 40 language-locales. No model-swapping. Punctuation and capitalization are built in. No separate post-processing step. Targets two workloads: low-latency streaming and high-throughput batch. NVIDIA still recommends its English-only model for English-only use. 02 — ARCHITECTURE Cache-Aware FastConformer-RNNT A 24-layer FastConformer encoder paired with an RNNT decoder. Buffered streaming re-processes overlapping audio windows at every step. This model caches encoder self-attention and convolution states, then reuses them. Each audio frame is processed exactly once, with no overlap. Compute and end-to-end latency drop, with no accuracy penalty. 03 — THE LATENCY KNOB One setting tunes latency vs. accuracy att_context_sizeChunk (latency)Use case [56,0]80ms (Ultra-Low)Ultra low latency voice agents [56,1]160ms (Low)Interactive voice agents [56,3]320ms (Balanced)Conversational AI, live caption [56,6]560ms (Medium)Higher accuracy, reasonable latency [56,13]1.12s (High)Highest accuracy Same checkpoint, chosen at inference time. No retraining required. 04 — LANGUAGES & DETECTION Coverage and automatic language ID 40 language-locales, including English, Spanish, Ge
Related
相關文章
Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are the first bidirectional members of the LFM family. They build on LFM2.5-350M-Base, released in March. The pair targets fast multilingual and cross-lingual search across 11 languages. Their footprint is small enough to run almost anywhere. Both are available now on Hugging Face under the LFM Open License v1.0. LFM2.5 Retrievers The two models share one backbone but represent text differently. LFM2.5-Embedding-350M is a dense bi-encoder. It turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index. LFM2.5-ColBERT-350M is a late-interaction model. It converts each token into a vector rather
Perplexity Launches Brain, a Self-Improving Memory System That Builds a Context Graph of an Agent’s Work and Learns Overnight
Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different path. Today, Perplexity launched Brain, a self-improving memory system for its agent product, Computer. Brain does not focus on remembering you. It remembers what the agent did. That reframes what memory in AI is for. What is Perplexity‘s Brain Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews that graph. It then teaches itself how to do the work better. The idea is straightforward. The more work you do, the more efficient Brain makes your Computer. Brain is rolling out today to Perplexity Max and Enterprise Max subscribers in Research Preview. Two Axes of AI Memory Perp

智譜新高,MiniMax承壓,“大模型雙雄”命運殊途
這篇消息聚焦「智譜新高,MiniMax承壓,“大模型雙雄”命運殊途」。原始導語提到:大模型在被市場重新定價 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

華為昇騰 0 Day 支持智譜 GLM-5.2 模型,提供全面推理優化
華為昇騰 AI 宣佈在智譜開源 GLM-5.2 大模型當天即完成深度推理優化。通過 MOE 大融合算子、通信計算融合、高併發調度等七項關鍵技術,顯著提升編程和長程任務的處理效率,現已支持 A3 系列產品部署。#AI 大模型# #國產算力#
企業AI轉型再添利器:青雲科技算力雲接入 MiniMax-M3 模型
企業AI落地面臨高效低成本難題。青雲科技旗下基石智算平臺接入國產開源大模型MiniMax-M3,提供新算力支持。MiniMax-M3以卓越上下文處理能力等三大核心技術見長,依託自研架構,助企業便捷部署AI業務。
阿里開源統一科學大模型 LOGOS,僅用五十六分之一參數超越微軟
阿里 ATH-Token Foundry 聯閤中國人民大學高瓴人工智能學院開源科學基礎模型 LOGOS。該模型採用統一科學語法與純序列建模範式,在六大科學任務上匹配或超越傳統專用方法。其中 LOGOS-1B 僅 1B 參數,即展現出極高效率,性能超越參數量達 8×7B 的微軟模型。