Anthropic推出Claude Sonnet 5

重點摘要
這篇消息聚焦「Anthropic推出Claude Sonnet 5」。原始導語提到:更多消息,持續更新中 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。
### Anthropic 推出 Claude Sonnet 5:新一代輕量級模型登場
人工智慧公司 Anthropic 近日正式發表 Claude Sonnet 5,這是其 Claude 系列模型的最新成員。雖然官方目前僅釋出簡短消息,細節仍在陸續更新中,但從產品命名與過往脈絡來看,Sonnet 系列向來定位於「輕量高效」的平衡點——比旗艦級 Opus 更快速、成本更低,同時又比入門款 Haiku 擁有更強的理解與生成能力。這次的版本迭代,預期將在推理準確度、多輪對話連貫性以及安全性上帶來顯著升級。
回顧 Claude 家族的發展歷程,Anthropic 始終強調「負責任的 AI」原則,尤其注重模型的安全對齊與可解釋性。Sonnet 5 很可能延續這項傳統,在訓練過程中導入更先進的紅隊測試與價值校準機制。此外,隨著業界對長上下文處理的需求日益增加,新模型或許會進一步擴展支援的 token 長度,讓開發者能夠處理更複雜的文件分析、程式碼審查或學術研究任務。
對開發者與企業用戶而言,Claude Sonnet 5 的推出意味著更多元的選擇。過往 Sonnet 系列因 API 定價親民、回應速度快,已成為許多中小型團隊建構聊天機器人、內容摘要工具的首選。新版若能在不犧牲速度的前提下提升邏輯推理能力,將有助於降低企業導入 AI 的門檻,尤其適合客服系統、自動化報告生成等需要即時反饋的場景。
從競爭格局來看,Anthropic 正面臨 OpenAI 的 GPT-4o、Google 的 Gemini 系列等強勁對手。Sonnet 5 的發布時機與規格,很可能瞄準「中階效能」這個關鍵市場區間——既不是最昂貴的頂規模型,也不是功能陽春的入門款。若能在成本與效能之間取得更佳平衡,便有機會吸引那些對預算敏感、但又希望維持一定品質的企業客戶。
值得注意的是,Anthropic 過去在模型透明度上著墨甚多,例如公開系統卡片(System Card)說明訓練資料與安全措施。讀者可以期待 Sonnet 5 的技術報告是否會揭露更多關於資料過濾、偏見緩解以及模型限制的細節。這不僅關乎學術研究,也直接影響企業在合規與風險管理上的決策。
此外,Sonnet 5 的 API 定價策略將是市場關注的焦點。若 Anthropic 能維持甚至調降每百萬 token 的費用,同時提升輸出品質,將有機會在價格戰中突圍。開發者社群也將密切關注新模型在程式碼生成、數學推理、多語言支援等基準測試上的表現,這些數據往往比官方宣傳更能反映真實使用體驗。
對於一般使用者而言,Claude Sonnet 5 可能率先在 Anthropic 的官方聊天平台 Claude.ai 上線,屆時可透過免費或付費方案體驗。建議讀者留意官方後續公布的更新,包括模型卡、API 文件以及第三方評測報告。隨著 AI 模型迭代速度加快,掌握第一手效能對比與應用案例,將有助於在個人工作流程或商業專案中做出更明智的選擇。
Related
相關文章

軟件沒被AI殺死,但全球市場都捲上天了
AI寫程式能力崛起,但軟體並未被取代,反而在全球市場面臨更加激烈的競爭。軟體開發的門檻降低,促使各國廠商紛紛投入,導致市場「捲」上加「捲」。軟體業者需在效率與創新之間找到新平衡,才能應對這場無止境的挑戰。
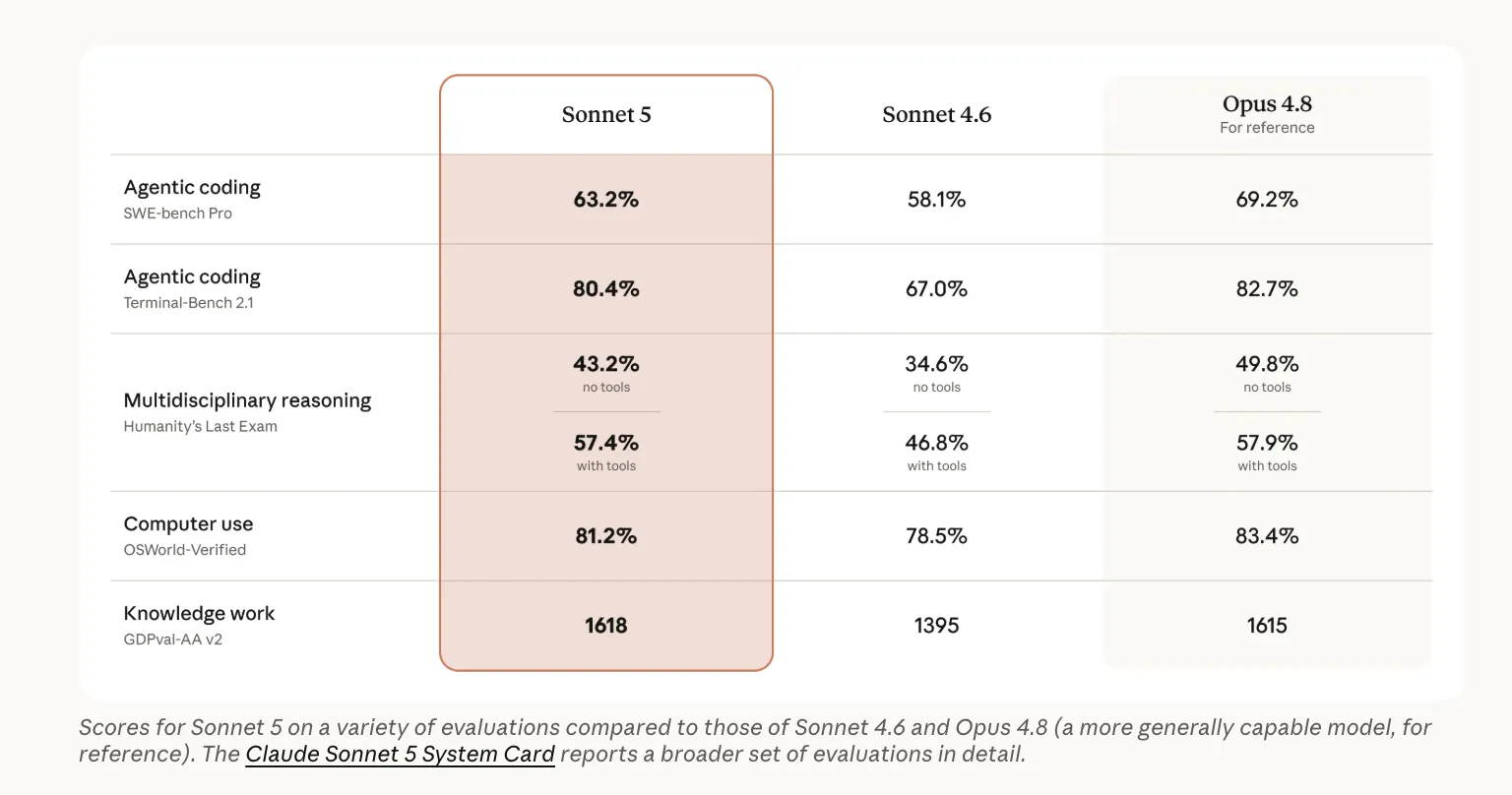
Anthropic Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8: Agentic Coding Benchmarks, API Pricing, and Cost-Performance Tradeoffs Compared
Anthropic just shipped Claude Sonnet 5. They call it its most agentic Sonnet model yet. It plans, drives browsers and terminals, and runs autonomously across long tasks. Sonnet 5 is the default model for Free and Pro plans today. Max, Team, and Enterprise users can select it. It is also live in Claude Code and on the Claude Platform. TL;DR Sonnet 5 is Anthropic’s most agentic mid-tier model, closing much of the gap to Opus 4.8. Beats Sonnet 4.6 on every published benchmark: 63.2% SWE-bench Pro, 81.2% OSWorld-Verified, 57.4% HLE. Cheaper to run: $2/$10 per MTok intro pricing through Aug 31, then $3/$15; Opus 4.8 is $5/$25. Best value at low/medium effort; at xhigh it can cost more than Opus 4.8 for similar quality. Safer than 4.6, with deliberately low cyber capability — Opus stays the pick

Token管夠的時代結束了
這篇消息聚焦「Token管夠的時代結束了」。原始導語提到:企業的錢也不是大風颳來的 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

Claude Code之父版「職場MBTI」:AI洗牌後只剩5類人,你選哪種?
這篇消息聚焦「Claude Code之父版「職場MBTI」:AI洗牌後只剩5類人,你選哪種?」。原始導語提到:未來是屬於這5種職業的 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。
中國信通院牽頭,首個智算運維智能體評測基準正式落地,覆蓋 5 款主流國產芯片
6月29日,在中國信通院人工智能軟硬件協同創新與適配驗證中心、中國人工智能產業發展聯盟、工信部人工智能標準化技術委員會聯合主辦的2026“眾智”大模型開放智算生態協同高級別研討會中,中國信通院副院長魏亮,正式發佈AISHPerf人工智能軟硬件基準體系3.0版本,包含兩項 AI Infra 領域核心評測基準——AISHPerf-智算運維智能體評測基準以及AISHPerf-算子生成智能體評測基準,兩大基準由國內頂尖AI原生基礎設施服務商無問芯穹及清華大學團隊作為重點技術支持方參與建設。前者是首個面向 AI Infra 的運維智能體評測基準,依託百億級真實運維數據構建,核心考核智算運維智能體在真實生產場景中解決實際問題的落地能力。後者則跳出 “模型能否生成可運行 GPU 算子” 的基礎維度,將評測重心錨定在 “模型生成的算子能否在真實量化推理部署中替代現有算子” 的工程可部署性上,更貼合產業實際落地需求。二者從底層算力優化到上層集群運維,共同為智算產業的標準化升級與高質量發展提供了統一的能力參照框架。 AISHPerf(Performance Benchmarks of Artificial Intelligence Software and Hardware)是中國信通院與人工智能大模型及軟硬件評測工業和信息化部重點實驗室,依託人工智能軟硬件協同創新與適配驗證中心(位於國家信創園)聯合構建的人工智能軟硬件基準體系,旨在設置多維度指標,考察端到端方案對模型及應用場景的真實承載能力,系統評估軟硬件各層級間的協同優化水平、兼容適配能力及整體交付效能。在此次發佈的兩項基準中,AISHPerf-智算運維智能體評測基準尤為引人注目,它不僅標誌著我國在智算集群運維智能體領域擁有了首個權威評測體系,更率先將國產芯片集群運維場景納入評測體系、填補了國產智算運維智能體評測領域的空白,為構建自主自治
Hermes新功能上線!比Opus 4.8和GPT-5.5還猛
AI應用風向標(公眾號:ZhidxcomAI) 作者|畢偉豪 編輯|漠影 智東西6月30日報道,現在,Fable 5和Mythos 5等頂尖閉源模型沒法使用,就算能用,單一模型也總有搞不定的問題,那麼,想要高質量輸出結果的用戶該怎麼辦呢? 近日,Hermes Agent上線了MoA(Mixture of Agents)功能,支持用戶自由組合多種模型作為虛擬模型使用,在Nous Research即將發佈的基準測試中,這個混合模型的評分超過了Opus 4.8 和GPT-5.5。 一、Fable 5、Mythos 5被禁,多模型組合成為潮流 Nous Research在官推上說了這樣一句話:“最強大的模型是受限的,只有少數人才能獲得訪問權限。”這句話明晃晃地指向了Fable 5等模型被封禁的事件。 在這種背景下,不難看出,MoA這個混合模型模式的終極目的,是用開源模型的組合達到頂尖閉源模型的水準,就像Hermes Agent聯合創始人Teknium說的,他們正在測試各種開源模型組合,看看是否能用更便宜的模型達到Opus的水平。 這種多模型組合比肩頂尖模型的思路,最近其實有不少實踐的例子,比如前段時間日本AI獨角獸Sakana AI發佈的Sakana Fugu系列編排器模型,會根據任務選擇最佳的模型來處理,和MoA的思路非常相似。 而MoA的技術也在很久之前就已存在了,2024年6月Together AI曾發表過一篇論文《Mixture-of-Agents Enhances Large Language Model Capabilities》,核心是多LLM組合,每一層模型都會參考上一層模型的輸出,再繼續生成自己的回答。同時,論文也將模型分成了兩類,也就是現在Hermes所用的參考模型和聚合模型。 當用戶提出問題時,參考模型會先對問題進行分析判斷,然後給出參考意見,隨後由聚合模型來