Liquid AI 推出 LFM2.5-8B-A1B:具備 83 億總參數與 15 億活躍參數的裝置端 MoE 模型
重點摘要
Liquid AI 正式發布 LFM2.5-8B-A1B,這是一款專為工具呼叫設計的裝置端混合專家(MoE)模型。該模型擁有 83 億總參數,但每次推論僅啟動 15 億參數,稀疏活化特性使其能在消費級硬體上運行。作為 LFM2 系列的最新版本,LFM2.5 延續混合模型架構,並加入 128K 上下文視窗、推理能力與擴增訓練。其架構包含 24 層,其中 18 層為雙門控 LIV 卷積區塊,6 層為 GQA 層,結合 MoE、分組查詢注意力與門控短卷積區塊,有效降低每個 token 的計算成本。
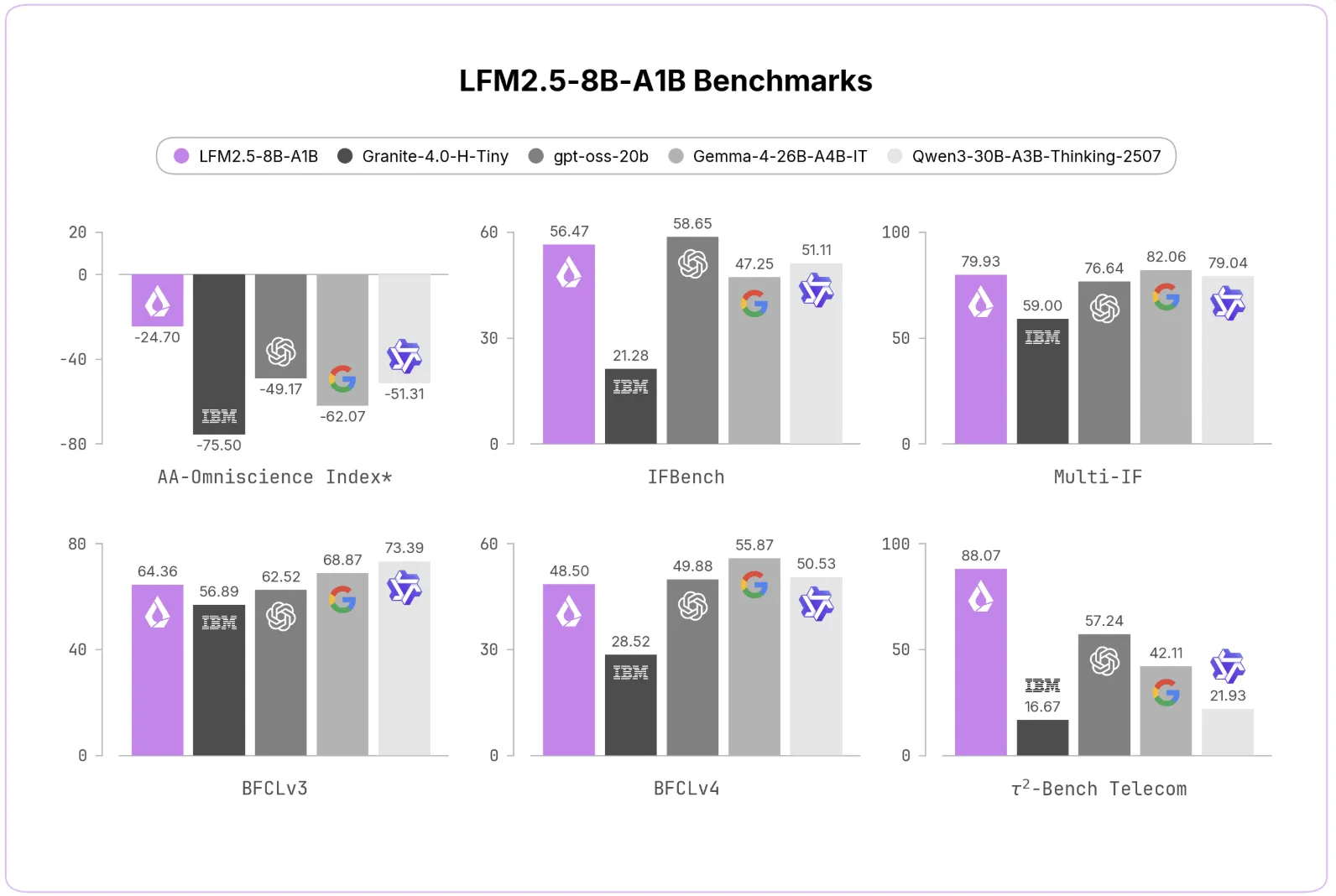
Liquid AI just shipped LFM2.5-8B-A1B. It is an on-device Mixture-of-Experts (MoE) model built for tool calling. The model holds 8.3B total parameters but activates only 1.5B per token. That sparsity is what lets it run on consumer hardware. The release follows LFM2-8B-A1B, which Liquid AI team published earlier. LFM2.5 is a new family of hybrid models for on-device deployment. This version adds a 128K context window, reasoning, and scaled-up training. What is LFM2.5-8B-A1B The model uses a sparse MoE design. It activates 1.5B of 8.3B total parameters per forward pass. That keeps each generated token cheap to compute. The architecture has 24 layers. Eighteen are double-gated LIV convolution blocks; six are GQA layers. It combines MoE, GQA, and gated short convolution blocks. The context length is 131,072 tokens. The model covers nine languages, including Arabic, Chinese, and Japanese. Liquid AI team recommends a temperature of 0.2, top_k of 80, and repetition_penalty of 1.05. Unlike its predecessor, LFM2.5-8B-A1B is a reasoning-only model. It produces an explicit chain of thought before its final answer. Liquid AI team chose this because MoE models run in compute-bound settings. A smaller active parameter count makes each reasoning token inexpensive. What Changed Since LFM2-8B-A1B Liquid expanded the context window from 32,768 to 128,000 tokens. Pretraining scaled from 12T to 38T tokens. The vocabulary doubled from 65,536 to 128,000 tokens. The larger vocabulary tokenizes non-Latin scripts more efficiently. Liquid AI team reports the strongest compression gains in Hindi, Thai, Vietnamese, Indonesian, and Arabic. The rest of the architecture stays the same as LFM2-8B-A1B. How Liquid AI Trained It Liquid AI team extended the tokenizer in place rather than retraining from scratch. It continued BPE merge training from the original merges on a multilingual corpus. New embedding rows initialize as the mean of their sub-token decompositions. A brief two-stage adaptation then recovers quality. Context extension came in two phases. A 2T token midtraining phase reached 32K, focused on reasoning, math, and tool use. Raising the RoPE base θ, plus a 400B token stage, reached 128K. Two reinforcement learning stages target known failure modes. A preference optimization stage reduces ‘doom loops’ in long reasoning traces. It redistributes probability mass toward plausible alternatives. A separate RL shaping reward discourages loop-inducing restart words like ‘Wait…’. Another RL stage uses an avg@k-based reward to cut hallucinations. The goal is abstention on queries beyond reliable knowledge. https://www.liquid.ai/blog/lfm2-5-8b-a1b The Benchmark Case LFM2.5-8B-A1B improves over its predecessor across the board. The AA-Omniscience Non-Hallucination Rate jumped from 7.46 to 63.47. IFEval rose from 79.44 to 91.84. MATH500 climbed from 74.80 to 88.76. Tau² Telecom rose from 13.60 to 88.07. Liquid AI team compared the model against dense and MoE alternatives. On instruction following, it matches Gemma-4-26B-A4B-IT on IFEval. It does so at a fraction of the active parameter count. On Tau² Telecom, it scores 88.07, ahead of much larger models. The avg@k reward drives a much lower hallucination rate. Accuracy stays reasonable for the model’s size. On agentic benchmarks, it remains competitive with bigger models. BenchmarkLFM2-8B-A1BLFM2.5-8B-A1BΔAA-Omniscience Non-Hallucination Rate7.4663.47+56.01IFEval79.4491.84+12.40MATH50074.8088.76+13.96Tau² Telecom13.6088.07+74.47 Running It: CPU, GPU, and Tooling The model ships with day-one support across the inference ecosystem. Frameworks include llama.cpp, MLX, vLLM, and SGLang. ONNX and Liquid’s LEAP edge platform are also supported. On CPU, it decodes 253 tokens/s on an M5 Max. It reaches 146 tokens/s on a Ryzen AI Max+ 395. It stays under 6 GB of memory throughout. On a phone, it holds about 30 tokens/s. On a single NVIDIA H100 SXM5, output throughput hits 18.5K tokens per second. That is over 1.6B tokens per day at high concurrency. For tool use, LFM2.5 writes Pythonic function calls by default. They appear between the <|tool_call_start|> and <|tool_call_end|> special tokens. You can override this to JSON in the system prompt. Strengths and What to Watch Strengths: Activates only 1.5B parameters, keeping inference cheap on edge hardware Competitive instruction-following and agentic scores for its size class 128K context window and nine-language coverage Open-weight under the LFM1.0 license, with base and post-trained checkpoints What to Watch: Limited knowledge capacity from the small active parameter count Not a fit for heavy programming or knowledge-intensive QA without retrieval Reasoning-only output adds chain-of-thought tokens to every turn Text-only; this variant has no vision or audio input Marktechpost’s Visual Explainer @import url('https://fonts.googleapis.com/css2?family=Fraunces:opsz,[email protected],500;9..144,600&family=JetBrains+Mono:wght@400;600&display=swap'); /* ---- scope reset / theme ---- */ #lfm25-guide-7c2e * { box-sizing:border-box !important; margin:0; padding:0; } #lfm25-guide-7c2e { --ink:#0A0B0D; --surface:#14171A; --raised:#1B2024; --cream:#ECEAE3; --muted:#9AA0A6; --line:#2A2F35; --teal:#20D5C4; --teal-deep:#12A89B; --sand:#E4D9C3; background:var(--ink) !important; color:var(--cream) !important; border:1px solid var(--line) !important; border-radius:18px !important; overflow:hidden; font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Helvetica,Arial,sans-serif; line-height:1.55; max-width:920px; margin:24px auto; position:relative; } /* ---- wpautop artifact suppression ---- */ #lfm25-guide-7c2e hr, #lfm25-guide-7c2e p:empty, #lfm25-guide-7c2e del, #lfm25-guide-7c2e s { display:none !important; } /* ---- progress bar ---- */ #lfm25-guide-7c2e .lf-progress { height:3px !important; width:100%; background:var(--line) !important; } #lfm25-guide-7c2e .lf-progress-fill { height:3px !important; width:12.5%; background:var(--teal) !important; transition:width .5s cubic-bezier(.4,0,.2,1); } /* ---- stage / track ---- */ #lfm25-guide-7c2e .lf-stage { position:relative; overflow:hidden; } #lfm25-guide-7c2e .lf-track { display:flex; align-items:stretch; transition:transform .55s cubic-bezier(.4,0,.2,1); will-change:transform; } #lfm25-guide-7c2e .lf-slide { flex:0 0 100%; width:100%; padding:44px 52px 40px !important; background:var(--ink) !important; min-height:540px; display:flex; flex-direction:column; } /* ---- typography ---- */ #lfm25-guide-7c2e .lf-eyebrow { font-family:'JetBrains Mono',monospace; font-size:11px; letter-spacing:.22em; text-transform:uppercase; color:var(--teal) !important; margin-bottom:18px; } #lfm25-guide-7c2e h2.lf-title { font-family:'Fraunces',Georgia,serif; font-weight:600; font-size:30px; line-height:1.12; color:var(--cream) !important; margin-bottom:14px; letter-spacing:-.01em; } #lfm25-guide-7c2e h2.lf-cover { font-family:'JetBrains Mono',monospace; font-weight:600; font-size:40px; letter-spacing:-.02em; color:var(--cream) !important; margin:6px 0 16px; } #lfm25-guide-7c2e .lf-lede { font-size:16px; color:var(--muted) !important; max-width:62ch; margin-bottom:22px; } #lfm25-guide-7c2e .lf-body { font-size:15px; color:var(--cream) !important; } /* ---- spec chips ---- */ #lfm25-guide-7c2e .lf-chips { display:flex; flex-wrap:wrap; gap:10px; margin-top:6px; } #lfm25-guide-7c2e .lf-chip { font-family:'JetBrains Mono',monospace; font-size:12.5px; padding:8px 13px !important; background:var(--surface) !important; border:1px solid var(--line) !important; border-radius:999px !important; color:var(--cream) !important; } #lfm25-guide-7c2e .lf-chip b { color:var(--teal) !important; font-weight:600; } /* ---- feature rows ---- */ #lfm25-guide-7c2e .lf-list { list-style:none; margin-top:6px; } #lfm25-guide-7c2e .lf-list li { position:relative; padding:13px 0 13px 26px !important; border-bottom:1px solid var(--line) !important; font-size:15px; color:var(--cream) !important; } #lfm25-guide-
Related
相關文章
Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are the first bidirectional members of the LFM family. They build on LFM2.5-350M-Base, released in March. The pair targets fast multilingual and cross-lingual search across 11 languages. Their footprint is small enough to run almost anywhere. Both are available now on Hugging Face under the LFM Open License v1.0. LFM2.5 Retrievers The two models share one backbone but represent text differently. LFM2.5-Embedding-350M is a dense bi-encoder. It turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index. LFM2.5-ColBERT-350M is a late-interaction model. It converts each token into a vector rather
Perplexity Launches Brain, a Self-Improving Memory System That Builds a Context Graph of an Agent’s Work and Learns Overnight
Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different path. Today, Perplexity launched Brain, a self-improving memory system for its agent product, Computer. Brain does not focus on remembering you. It remembers what the agent did. That reframes what memory in AI is for. What is Perplexity‘s Brain Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews that graph. It then teaches itself how to do the work better. The idea is straightforward. The more work you do, the more efficient Brain makes your Computer. Brain is rolling out today to Perplexity Max and Enterprise Max subscribers in Research Preview. Two Axes of AI Memory Perp

智譜新高,MiniMax承壓,“大模型雙雄”命運殊途
這篇消息聚焦「智譜新高,MiniMax承壓,“大模型雙雄”命運殊途」。原始導語提到:大模型在被市場重新定價 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

華為昇騰 0 Day 支持智譜 GLM-5.2 模型,提供全面推理優化
華為昇騰 AI 宣佈在智譜開源 GLM-5.2 大模型當天即完成深度推理優化。通過 MOE 大融合算子、通信計算融合、高併發調度等七項關鍵技術,顯著提升編程和長程任務的處理效率,現已支持 A3 系列產品部署。#AI 大模型# #國產算力#
企業AI轉型再添利器:青雲科技算力雲接入 MiniMax-M3 模型
企業AI落地面臨高效低成本難題。青雲科技旗下基石智算平臺接入國產開源大模型MiniMax-M3,提供新算力支持。MiniMax-M3以卓越上下文處理能力等三大核心技術見長,依託自研架構,助企業便捷部署AI業務。
阿里開源統一科學大模型 LOGOS,僅用五十六分之一參數超越微軟
阿里 ATH-Token Foundry 聯閤中國人民大學高瓴人工智能學院開源科學基礎模型 LOGOS。該模型採用統一科學語法與純序列建模範式,在六大科學任務上匹配或超越傳統專用方法。其中 LOGOS-1B 僅 1B 參數,即展現出極高效率,性能超越參數量達 8×7B 的微軟模型。