Google DeepMind 推出 Gemma 4 12B:免編碼器多模態模型,原生支援音訊,可在 16GB 筆電上執行
重點摘要
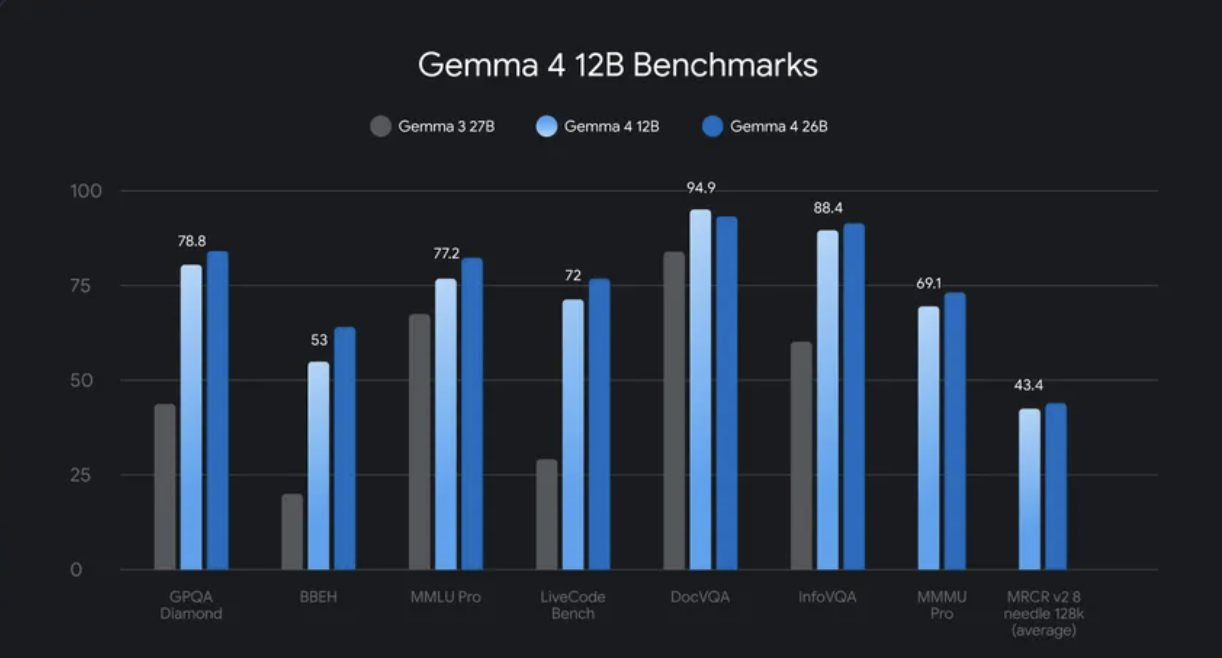
Google DeepMind 今日正式釋出 Gemma 4 12B,這是一款密集多模態模型,完全捨棄傳統編碼器。視覺與音訊資料直接流入大型語言模型主幹。結果是:該模型能在配備 16GB RAM 的消費級筆電上執行代理工作流程。採用 Apache 2.0 授權釋出。 模型概述與取得方式 Gemma 4 12B 是一個 120 億參數的純解碼器 Transformer,原生處理文字、圖像、音訊與影片,無需獨立的視覺或音訊編碼器。解碼器結構與 Gemma 4 31B Dense 模型相同,銜接了邊緣友善的 E4B 與更大的 26B 混合專家變體之間的差距。 架構:統一的、免編碼器純解碼器 Transformer。 模態:文字、圖像、影片與原生音訊輸入——這是首款中等尺寸的 Gemma,具備…
Google DeepMind just released Gemma 4 12B, a dense multimodal model that strips out traditional encoders entirely. Vision and audio flow straight into the LLM backbone. The result is a model that runs agentic workflows on a consumer laptop with 16 GB of RAM. It ships under the Apache 2.0 license. Model Overview & Access Gemma 4 12B is a 12-billion-parameter decoder-only transformer. It handles text, images, audio, and video natively. There are no separate vision or audio encoders. The decoder uses the same structure as the Gemma 4 31B Dense model. It bridges the gap between the edge-friendly E4B and the larger 26B Mixture of Experts variant. Architecture: Unified, encoder-free decoder-only transformer. Modalities: Text, image, video, and native audio input — the first mid-sized Gemma with audio. Hardware requirement: 16 GB VRAM or unified memory. Runs on consumer GPU laptops and Apple Silicon Macs. License: Apache 2.0. Weights are open and publicly downloadable. Inference stack: Compatible with llama.cpp, MLX, vLLM, Ollama, SGLang, Unsloth, and LM Studio. Download: Hugging Face and Kaggle. The instruct variant is google/gemma-4-12B-it. Integration: Hugging Face Transformers, LiteRT-LM CLI, and an OpenAI-compatible local API server via litert-lm serve. A dedicated Multi-Token Prediction (MTP) drafter model is also released. It reduces inference latency on local hardware. Architecture: The Encoder-Free Design Every prior mid-sized Gemma model used separate Transformer encoders for vision and audio. Those encoders added latency and parameter overhead. The medium-sized Gemma 4 models carry a 550M-parameter vision encoder. The E2B and E4B models include a 300M-parameter audio encoder. All of that is gone in the 12B. Vision embedder (35M parameters): Raw images are split into 48×48 pixel patches. Each patch is projected to the LLM’s hidden dimension with a single matrix multiplication. There is no attention layer; each patch is processed independently. Spatial position is injected using a factorized coordinate lookup: a learned X matrix and a learned Y matrix. For a patch at (x, y), the model looks up two learned embeddings and adds them to form a position vector. This is added to the patch embedding, followed by normalization. That is the entire vision pipeline. Audio wave projection: Raw 16 kHz audio is sliced into 40 ms frames. Each frame contains 640 values. Those values are linearly projected into the same embedding space as text tokens. There is no feature extraction and no conformer layers. The LLM’s existing Rotary Position Embedding (RoPE) handles the 1-D temporal sequence. The audio encoder in the E2B and E4B used 12 conformer layers. All of that is removed. Importance: The unified weight space means you no longer co-tune separate frozen encoders. Downstream fine-tuning with LoRA or full tuning updates vision, audio, and text processing in a single pass. Hugging Face Transformers and Unsloth already support this. The encoder-free design reduces multimodal latency. The LLM backbone starts processing immediately. No encoder must finish first. Capabilities & Performance Google DeepMind team has not published full benchmark results in the initial launch materials. The official release notes state the 12B model performs nearing the 26B MoE model on standard benchmarks, at less than half the total memory footprint. https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/ The model’s demonstrated capabilities include: Automatic speech recognition. Transcribes audio natively without an external ASR pipeline. Agentic reasoning. Runs multi-step workflows locally, with performance approaching the 26B MoE model. Diarization. Distinguishes speakers in audio input. Video understanding. Processes video frames alongside audio. A demo analyzed a 5-minute Google I/O keynote segment using 313 frames at 1 FPS with a visual token budget of 70 per frame. Coding. Built a Gradio image-processing app using its own code generation, served locally with llama.cpp. Multimodal agentic workflows. The official Gemma Skills repository at github.com/google-gemma/gemma-skills provides pre-built agent capabilities. In Google’s own Google AI Edge Eloquent app, the switch to Gemma 4 12B produced what Google reports as a 60%+ jump in overall quality, with improved instruction following and scope adherence. Marktechpost’s Visual Explainer #mtp-g4-slider hr, #mtp-g4-slider p:empty, #mtp-g4-slider del, #mtp-g4-slider s { display:none !important; } #mtp-g4-slider *{ box-sizing:border-box !important; margin:0; padding:0; } #mtp-g4-slider{ --g-blue:#4285F4; --g-red:#EA4335; --g-yellow:#FBBC04; --g-green:#34A853; --g-ink:#202124; --g-grey:#5f6368; --g-line:#dadce0; --g-surface:#f8f9fa; font-family:'Google Sans','Product Sans',Roboto,Arial,sans-serif !important; color:var(--g-ink) !important; background:#ffffff !important; border:1px solid var(--g-line) !important; border-radius:20px !important; max-width:840px; margin:24px auto; overflow:hidden; box-shadow:0 1px 3px rgba(60,64,67,.16), 0 8px 28px rgba(60,64,67,.10); } /* four-color brand bar */ #mtp-g4-slider .mtpg4-bar{ display:flex; height:6px; width:100%; } #mtp-g4-slider .mtpg4-bar span{ flex:1; } #mtp-g4-slider .mtpg4-bar span:nth-child(1){ background:var(--g-blue) !important; } #mtp-g4-slider .mtpg4-bar span:nth-child(2){ background:var(--g-red) !important; } #mtp-g4-slider .mtpg4-bar span:nth-child(3){ background:var(--g-yellow) !important; } #mtp-g4-slider .mtpg4-bar span:nth-child(4){ background:var(--g-green) !important; } #mtp-g4-slider .mtpg4-viewport{ overflow:hidden; position:relative; } #mtp-g4-slider .mtpg4-track{ display:flex; transition:transform .45s cubic-bezier(.4,0,.2,1); } #mtp-g4-slider .mtpg4-slide{ min-width:100%; padding:38px 44px 30px; } #mtp-g4-slider .mtpg4-eyebrow{ display:inline-block; font-size:12px; font-weight:700; letter-spacing:.10em; text-transform:uppercase; padding:5px 12px; border-radius:999px; background:var(--g-surface) !important; color:var(--g-grey) !important; border:1px solid var(--g-line) !important; margin-bottom:16px; } #mtp-g4-slider .mtpg4-slide h2{ font-size:27px; line-height:1.2; font-weight:700; color:var(--g-ink) !important; margin-bottom:8px; letter-spacing:-.01em; } #mtp-g4-slider .mtpg4-slide h3{ font-size:15px; font-weight:500; color:var(--g-grey) !important; margin-bottom:20px; } #mtp-g4-slider .mtpg4-slide p.lead{ font-size:16px; line-height:1.6; color:var(--g-ink) !important; max-width:62ch; margin-bottom:18px; } #mtp-g4-slider ul.mtpg4-list{ list-style:none !important; padding:0 !important; } #mtp-g4-slider ul.mtpg4-list li{ position:relative; padding:11px 14px 11px 18px; margin-bottom:10px; font-size:15px; line-height:1.5; color:var(--g-ink) !important; background:var(--g-surface) !important; border-radius:10px; border-left:4px solid var(--accent) !important; } #mtp-g4-slider ul.mtpg4-list li b{ font-weight:700; } #mtp-g4-slider code{ font-family:'Roboto Mono',ui-monospace,monospace !important; font-size:13px; padding:2px 6px; border-radius:5px; background:#ffffff !important; color:var(--g-blue) !important; border:1px solid var(--g-line) !important; } /* per-slide accent */ #mtp-g4-slider .mtpg4-slide[data-accent="blue"]{ --accent:var(--g-blue); } #mtp-g4-slider .mtpg4-slide[data-accent="red"]{ --accent:var(--g-red); } #mtp-g4-slider .mtpg4-slide[data-accent="yellow"]{ --accent:var(--g-yellow); } #mtp-g4-slider .mtpg4-slide[data-accent="green"]{ --accent:var(--g-green); } #mtp-g4-slider .mtpg4-slide .mtpg4-eyebrow{ color:var(--accent) !important; border-color:var(--accent) !important; } /* controls */ #mtp-g4-slider .mtpg4-nav{ display:flex; align-items:center; justify-content:space-between; padding:14px 24px; border-top:1px solid var(--g-line) !important; background:#ffffff !important; } #mtp-g4-slider .mtpg4-dots{ display:flex; gap:8px; } #mtp-g4-slider .mtpg4-dot{ width:8px; height:8px; border-radius:999px; border:none !important; backgrou
Related
相關文章

Edge AI Daily 早報(6月19日)
AI Engineer World's Fair 2026規模再創新高,標誌AI工程從幕後走向舞臺中央。行業面臨結構性調整:楊立昆警示OpenAI年虧210億美元揭示商業模式脆弱性,Transformer之父轉投OpenAI反映人才爭奪白熱化。Anthropic多線佈局——語音支持七種語言、加入碳清除聯盟、落子首爾辦事處,展現生態擴張野心。監管壓力加劇,意大利依據DMA調查蘋果iCloud,巴西開放iOS側載佣金降至5%,蘋果圍牆花園持續崩塌。

今天起,Claude Design要把設計師和程序員變成同一種人了
猝不及防!Anthropic深夜甩出Claude Design大更新,設計系統一鍵導入,代碼雙向同步,9大平臺一鍵導出。Anthropic設計師親自下場錄屏:AI跑了八輪自查,才敢把設計稿給你看。

OpenAI 成為 Rust 基金會白金會員,合計贊助 60 萬美元
OpenAI 正式成為 Rust 基金會白金會員,將提供總計 60 萬美元資金,用於支持 Rust 開源項目維護者及 Rust 創新實驗室等計劃。這標誌著 AI 巨頭對安全、高效系統編程語言的重視。 #OpenAI #Rust #開源

Claude Design 上線首周用戶破百萬,和 Claude Code 共享 AI 配額
Anthropic 今天(6 月 18 日)發佈公告,在宣佈 Claude Design 上線首周用戶規模突破 100 萬後,進一步強化和 Claude Code 的雙向聯動,實現從設計到編程的無縫工作流。
谷歌時隔6年再發智能音箱,Gemini上桌,售價不到700元
智東西 編譯 | 劉煜 編輯 | 陳駿達 智東西6月18日消息,谷歌昨日宣佈,其首款搭載居家版Gemini語音助手的智能音箱(Google Home Speaker)已開啟預售,將於當地時間6月25日正式上市,售價為99.99美元(約合人民幣677.03元)。在此之前,谷歌已有6年沒有推出過獨立智能音箱產品。 谷歌這款智能音箱外觀近似球形,風格類似亞馬遜新一代Echo音箱與蘋果舊款音箱HomePod Mini。 ▲谷歌智能音箱(圖源:谷歌官網) 使用音箱時,用戶只需通過口令“Hey Google”或“OK Google”喚醒Gemini,就可以繼續下達相應指令。這與谷歌舊款音箱、智能顯示屏等喚醒語音助手的方式相同。此外,用戶只要按照日常說話習慣下達命令,Gemini便能理解用戶意圖,相比之前大大提升溝通效率。 一、加強短時對話記憶,會員可與Gemini不限次數對話 谷歌此次推出的全新音箱升級諸多功能。其中,音箱搭載的Gemini語音助手擁有10款全新擬人化語音音色,用戶可以根據喜好自行選擇聲線。音箱還可支持用戶一次性下達多條語音指令,即使指令未能說對、說完整,用戶中途改口Gemini也能識別。 Gemini還具備多鏈路推理能力,落地到實際生活場景中比較實用。例如,用戶問:“我支持的足球隊下場比賽天氣如何?”Gemini收到指令後,會自動查詢賽事時間、舉辦地點,同時匹配相應時段天氣,再給出答覆。 同時,Gemini加強了短時對話記憶,能承接上下文實現連續對話功能。即使用戶連續追問、甚至串聯多項任務、不重複交代前置條件,該語音助手也能實現來回連貫交流。 ▲谷歌Gemini對話場景(圖源:谷歌官網) 不僅如此,Gemini搭配的連續對話功能,能讓應答後的音箱麥克風保持短暫收音,用戶無需重複喊“OK Google”就能繼續提問。該功能現已全面支持所有Gemini原生適配的語言,包括

微軟,考慮接入DeepSeek
這篇消息聚焦「微軟,考慮接入DeepSeek」。原始導語提到:Copilot Cowork轉為按量計費。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。