中國第一、全球第二!HiDream-O1-Image-1.5 登頂文生圖榜單,超越谷歌、英偉達
重點摘要
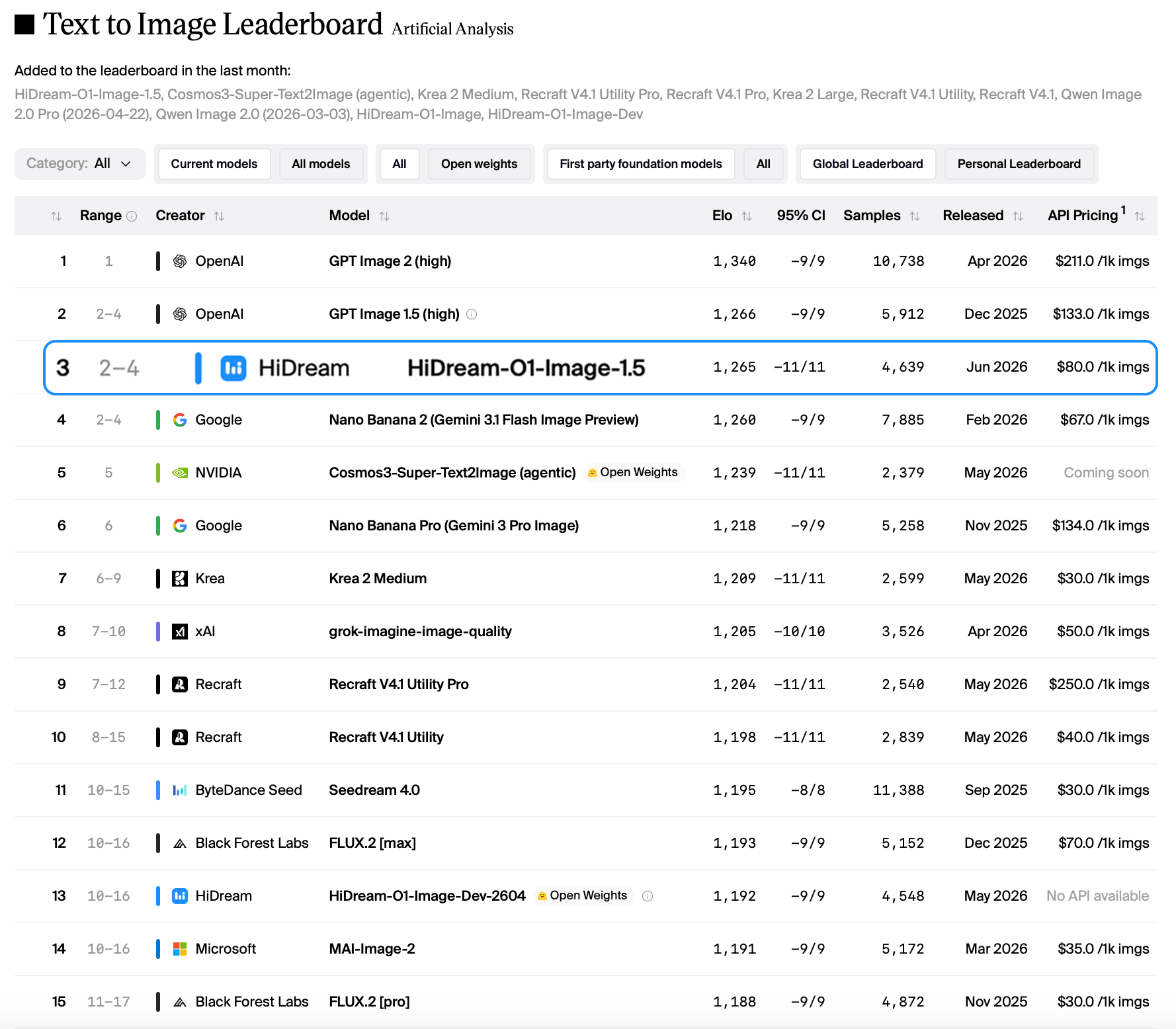
中国AI模型HiDream-O1-Image-1.5在文生图领域排名全球第二、中国第一,超越了Google和NVIDIA等公司。该模型由智象未来开发,展现出强大的图像生成能力。
### 重點整理
近期,一款名為 HiDream-O1-Image-1.5 的 AI 文生圖模型在國際評測榜單上表現亮眼,不僅在中國同類技術中奪下第一,更在全球排名中躍升至第二位,一舉超越 Google 與 NVIDIA 等科技巨頭的競品。這項成果由相關研究團隊發布,顯示出中國在生成式 AI 領域的競爭力正持續強化,尤其在圖像生成這塊技術密集的賽道上,已能與國際一線廠商分庭抗禮。
### 背景脈絡
文生圖(Text-to-Image)技術近年來發展迅速,從早期的 DALL·E、Stable Diffusion 到 Midjourney,再到各大雲端與晶片業者推出的模型,競爭日益白熱化。Google 的 Imagen、NVIDIA 的 eDiff-I 等模型曾長期佔據榜單前列,但 HiDream-O1-Image-1.5 的出現打破了這份壟斷。該模型可能在架構上採用了更高效的注意力機制或訓練策略,從而提升生成圖片的畫質、一致性與對文字提示的理解力。值得注意的是,這並非首次中國團隊在 AI 模型中取得突破,但直接超越兩大科技巨頭仍極具指標性意義。
### 可能影響
此次榜單變動對全球 AI 產業的影響可分為幾個層面。首先,**產業競爭版圖重新洗牌**:過去外界常認為美國企業獨占鰲頭,如今中國團隊的進展將迫使 Google、NVIDIA 加快迭代速度,也可能帶動更多開源或商業授權的模型出現。其次,**技術路線的驗證**:HiDream-O1-Image-1.5 的成功可能代表某種架構或訓練方法的優越性,例如更優秀的 CLIP 對齊、擴散模型改良或混合專家系統,這會引導學術界與業界的研發方向。第三,**應用成本與可及性**:若該模型能開放 API 或提供輕量版本,將降低中小企業與創作者對圖像生成工具的使用門檻,進一步催生更多 AI 繪圖應用場景。
### 讀者可關注的後續
對於關注 AI 發展的讀者,建議留意以下幾件事:**一、榜單評測標準的細節**:HiDream-O1-Image-1.5 是在哪個評測體系(例如 COCO、FID、CLIP Score 或人工評審)中勝出?這關係到其真實效能與應用範圍。**二、開放性與普及度**:該模型是否公開權重、模型卡或演示網站?若僅是內部測試,則實際影響力有限;若能開源或提供商用授權,將大幅改變市場格局。**三、與硬體的適配**:NVIDIA 被超越後,是否會推出針對自家 GPU 的最佳化版本來反制?而 HiDream 的模型是否需要特殊硬體才能運行?這會影響消費者的設備選擇。**四、倫理與監管動態**:隨著中國 AI 模型突破,各國在圖像生成的版權、假訊息控管等議題上,可能出現新的政策討論,這也是科技倫理領域值得追蹤的焦點。
### 總結觀點
HiDream-O1-Image-1.5 的登頂,不僅是單一技術的勝利,更象徵 AI 產業的全球化競爭已從「追趕」進入「並跑」階段。然而,榜單排名僅是參考指標之一,模型在實際場景中的穩定性、可控性與商業化能力,仍須長期觀察。對於台灣讀者而言,此事件提醒我們應持續關注跨國 AI 技術的動態,並思考在地的應用機會與風險管理。未來半年內,文生圖領域很可能迎來新一輪的模型發布潮,使用者與投資者都需做好準備。
Related
相關文章
Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are the first bidirectional members of the LFM family. They build on LFM2.5-350M-Base, released in March. The pair targets fast multilingual and cross-lingual search across 11 languages. Their footprint is small enough to run almost anywhere. Both are available now on Hugging Face under the LFM Open License v1.0. LFM2.5 Retrievers The two models share one backbone but represent text differently. LFM2.5-Embedding-350M is a dense bi-encoder. It turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index. LFM2.5-ColBERT-350M is a late-interaction model. It converts each token into a vector rather
Perplexity Launches Brain, a Self-Improving Memory System That Builds a Context Graph of an Agent’s Work and Learns Overnight
Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different path. Today, Perplexity launched Brain, a self-improving memory system for its agent product, Computer. Brain does not focus on remembering you. It remembers what the agent did. That reframes what memory in AI is for. What is Perplexity‘s Brain Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews that graph. It then teaches itself how to do the work better. The idea is straightforward. The more work you do, the more efficient Brain makes your Computer. Brain is rolling out today to Perplexity Max and Enterprise Max subscribers in Research Preview. Two Axes of AI Memory Perp

智譜新高,MiniMax承壓,“大模型雙雄”命運殊途
這篇消息聚焦「智譜新高,MiniMax承壓,“大模型雙雄”命運殊途」。原始導語提到:大模型在被市場重新定價 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

華為昇騰 0 Day 支持智譜 GLM-5.2 模型,提供全面推理優化
華為昇騰 AI 宣佈在智譜開源 GLM-5.2 大模型當天即完成深度推理優化。通過 MOE 大融合算子、通信計算融合、高併發調度等七項關鍵技術,顯著提升編程和長程任務的處理效率,現已支持 A3 系列產品部署。#AI 大模型# #國產算力#
企業AI轉型再添利器:青雲科技算力雲接入 MiniMax-M3 模型
企業AI落地面臨高效低成本難題。青雲科技旗下基石智算平臺接入國產開源大模型MiniMax-M3,提供新算力支持。MiniMax-M3以卓越上下文處理能力等三大核心技術見長,依託自研架構,助企業便捷部署AI業務。
阿里開源統一科學大模型 LOGOS,僅用五十六分之一參數超越微軟
阿里 ATH-Token Foundry 聯閤中國人民大學高瓴人工智能學院開源科學基礎模型 LOGOS。該模型採用統一科學語法與純序列建模範式,在六大科學任務上匹配或超越傳統專用方法。其中 LOGOS-1B 僅 1B 參數,即展現出極高效率,性能超越參數量達 8×7B 的微軟模型。