Meituan Releases LongCat-2.0: A 1.6T-Parameter Open MoE Model with Native 1M Context and LongCat Sparse Attention
重點摘要
Meituan has released LongCat-2.0, a large-scale Mixture-of-Experts (MoE) language model. It carries 1.6 trillion total parameters and activates about 48 billion per token.
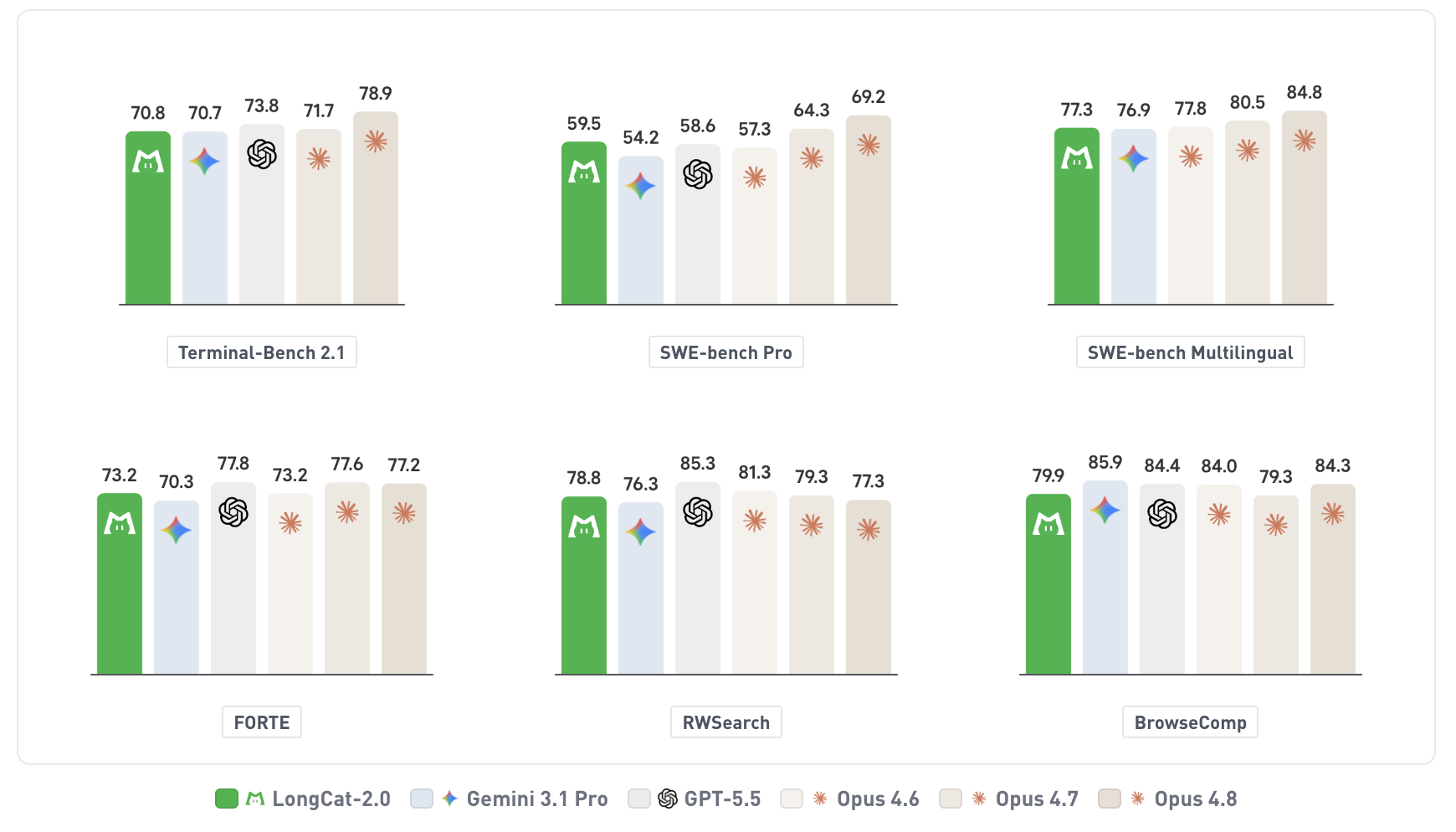
美團近日正式發表了新一代大規模語言模型 LongCat-2.0,這是一款採用混合專家(Mixture-of-Experts,MoE)架構的開源模型,總參數量達到 1.6 兆(1.6 trillion),在每次推理時僅激活約 480 億個參數。這項技術突破不僅延續了美團在 AI 基礎模型領域的布局,也為代理式程式碼生成(agentic coding)場景提供了更強大的支援。 LongCat-2.0 最引人矚目的特點之一,是原生支援 100 萬個 token 的上下文視窗(native 1-million-token context window)。這項能力意味著模型能夠一次性處理長達數百頁的程式碼文件、技術文件或複雜的對話歷史,而不需要依賴外部檢索或分段處理,大幅提升了在真實開發環境中的實用性。 此外,LongCat-2.0 的訓練與推理過程完全建立在國產 AI 專用 ASIC 超級節點(superpods)之上。這項選擇顯示美團在硬體生態上的策略轉向,不僅降低對國際 GPU 供應鏈的依賴,也驗證了國產晶片在超大規模模型訓練上的可行性。對於長期關注 AI 算力自主化的業界而言,這是一個值得注意的里程碑。 在模型架構方面,LongCat-2.0 採用了美團稱之為「LongCat Sparse Attention」的稀疏注意力機制。這項技術能夠在處理超長序列時有效降低計算量,同時保持對關鍵資訊的捕捉能力,使得百萬級上下文的推論效率得以實用化。這與傳統稠密注意力模型相比,在記憶體佔用和延遲控制上都有顯著改善。 LongCat-2.0 的前身是 2025 年推出的 LongCat-Flash,該模型參數量為 5600 億(560B),同樣採用 MoE 架構,但當時並未支援百萬級上下文。經過約一年的迭代,美團將參數規模擴大近三倍,並在上下文長度上實現了數量級躍升,顯示出團隊在模型擴展與稀疏計算最佳化方面的技術積累。 這款模型的主要目標場景是「agentic coding」,也就是讓 AI 不僅能理解與生成程式碼,還能直接嵌入到代理工作流程中執行程式碼。這類應用常見於自動化測試、程式碼審查、除錯助手、以及持續整合/持續部署產線中的智能排錯。LongCat-2.0 的超長上下文能力特別適合處理大型專案中的跨檔案依賴關係,或是在單一對話中追踪多個版本的變更記錄。 美團選擇將 LongCat-2.0 以開源形式釋出,這意味著學術界與開發者社群可以直接取得模型權重與技術細節,進行二次開發或部署。開源策略有助於加速生態系的建立,同時也讓外界有機會驗證模型在國產硬體上的實際表現。目前美團尚未公布具體的開源授權條款及模型下載渠道,但預計將在近期內於官方平台公開。 值得注意的是,1.6 兆總參數的規模讓 LongCat-2.0 躋身當前最大開源語言模型之列。儘管每次推論只激活 480 億參數,但由於 MoE 架構的特性,模型具備豐富的專家模組,能夠在不同任務中動態選擇最合適的路徑,這使得在參數效率與任務表現之間取得良好平衡。 從技術路線來看,美團並未跟隨主流業者採用純稠密模型或純 Transformer 架構,而是持續深耕 MoE 與稀疏注意力機制。這條路線在處理超長序列時具有先天優勢,尤其適合程式碼領域中常見的長尾依賴與大檔次上下文需求。此外,全面採用國產 ASIC 進行訓練,也為其他中國企業在算力受限環境下發展大模型提供了參考案例。 目前 LongCat-2.0 的具體評測數據尚未公開,但美團表示,在內部代理程式碼任務的測試中,模型在程式碼生成準確率、長上下文理解、以及多輪對話一致性等指標上,均超越了 LongCat-Flash 與同等規模的開源競品。隨著開源釋出,獨立研究機構與開發者社群將有機會進行更全面的基準測試。 對於 AI 開發者而言,LongCat-2.0 的出現意味著一個新的選擇:既不需要高價的 GPU 叢集,也能在國產硬體上運行百萬級上下文的模型。這可能降低中小型團隊進入代理式程式碼開發領域的門檻,同時也為中國 AI 晶片生態提供了一個實際的驗證場景。 美團在 AI 領域的布局並非僅限於語言模型,該公司過去已在智慧配送、自動駕駛、語音辨識等場景累積了大量 AI 應用經驗。LongCat-2.0 的發表,可以被視為美團將技術能力從垂直場景向通用基礎模型延伸的關鍵一步。未來若能將模型整合進美團的內部服務平台,例如自動化客服、程式碼審查、或營運分析,其商業價值將進一步放大。 總體而言,LongCat-2.0 在參數規模、上下文長度、硬體路徑與應用場景四個維度上都展現了明確的技術主張。隨著開源社群的回饋與更多測試結果的公布,這款模型在代理式程式碼領域的實際表現將逐步明朗。對於關注大模型發展趨勢的讀者而言,LongCat-2.0 無疑是一個值得持續追蹤的對象。
Related
相關文章

剛剛,LeCun團隊讓世界模型學會持續學習!
< img id="wx_img" src="https://www.qbitai.com/wp-content/uploads/imgs/qbitai-logo-1.png" width="400" height="400"> 剛剛,LeCun團隊讓世界模型學會持續學習!

Edge AI Daily 早報(7月5日)
Edge AI Daily 早報(7月5日)Edge AI Daily2026.07.05 08:39 · 來自北京全文4277字00:00 / 11:57Anthropic發佈Claude Fable 5編碼模型實現SWE-bench 95.0%突破,同時啟動內部藥物發現項目Claude Science,標誌AI公司從工具提供商向垂直領域深度滲透。
LlamaIndex ‘legal-kb’: Agentic Retrieval over Index v2 with retrieve, find, read, and grep Tools
LlamaIndex has published legal-kb, a public reference application on GitHub. It is described as a knowledge base for legal documents, powered by LlamaIndex Index v2 (the LlamaParse Platform).

趁火打劫,GPT-5.6三大模型全曝,定檔7月7日?
GPT-5.6 的三個模型底層代碼提前曝光,傳出將於下週二(7 月 7 日)正式發布。外界推測 OpenAI 刻意選在競爭對手 Claude 的關鍵時間點發布,意圖以高額度策略截殺對手氣勢。目前官方尚未證實模型細節與具體功能,但 7 月 7 日的發布已被視為業界重大事件。
光象科技累計完成數億元天使輪融資,佈局物理原生基座模型
量子位 消息指出,光象科技近日宣布,公司已累计完成数亿元天使轮融资,资金将主要用于布局物理原生基座模型的研发。这一融资事件表明市场对该公司在物理原生技术领域的前景充满信心,并为其后续技术突破与商业化落地提供了重要支持。

網友反饋 Claude Fable 5 重上架版“降智”,嚴苛 AI 護欄致頻繁回退 Opus 4.8
科技媒體 bleepingcomputer 昨日(7 月 3 日)發佈博文,報道稱 Anthropic 本月重新上架 Claude Fable 5 最強模型,除了額度限制外,多名用戶反饋存在“降智”情況,且更頻繁回退到 Opus 4.8 模型。