NVIDIA Releases Cosmos 3: A Two-Tower Mixture-of-Transformers Foundation Model Unifying Physical Reasoning, World Generation, and Action Generation
重點摘要
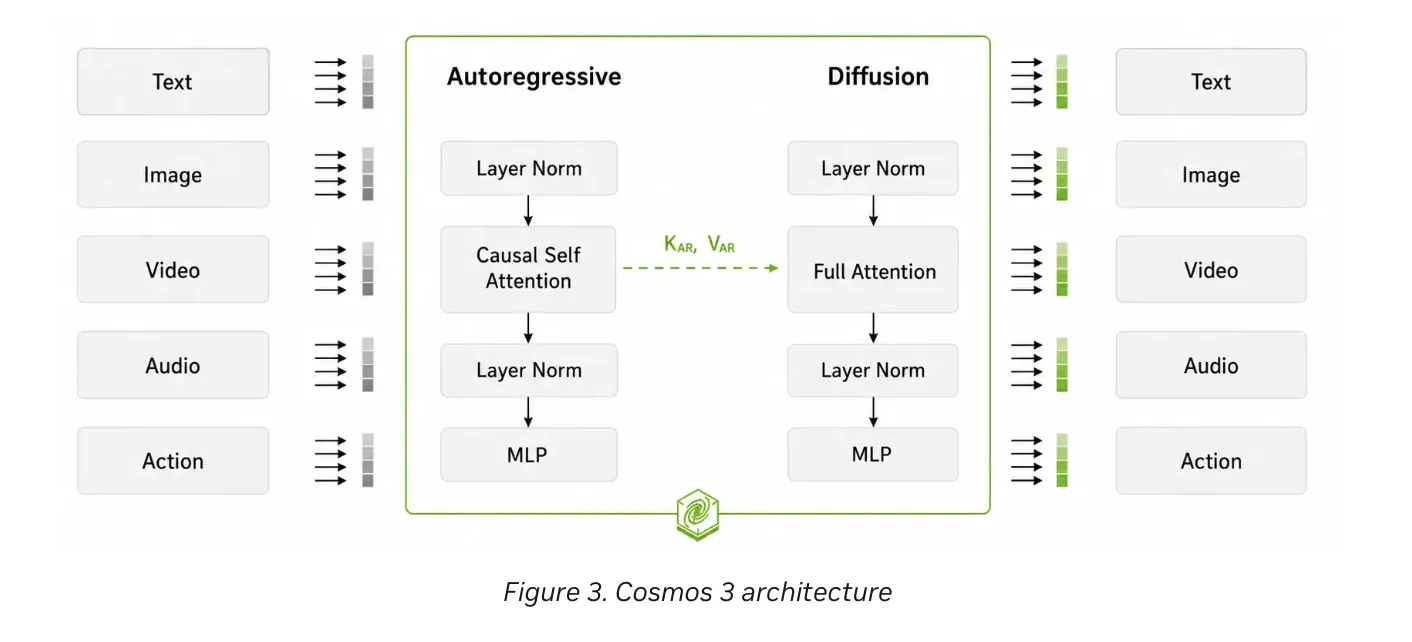
NVIDIA AI team have released Cosmos 3. It is a family of omnimodal world models for physical AI. The models combine physical reasoning, world generation, and action generation. All three capabilities live inside one open model. NVIDIA open sourced the checkpoints, training scripts, deployment tools, and datasets. The Cosmos 3 release targets robotics, autonomous vehicles, and warehouse monitoring teams. NVIDIA Cosmos 3 Physical AI systems must understand the world before acting in it. Robots and vehicles need to perceive, predict, and then act. Earlier Cosmos releases split these jobs across separate models. Cosmos 3 unifies them with a Mixture-of-Transformers (MoT) architecture. The architecture is built around two towers. The reasoner tower is a vision-language model (VLM). It interprets
NVIDIA AI team have released Cosmos 3. It is a family of omnimodal world models for physical AI. The models combine physical reasoning, world generation, and action generation. All three capabilities live inside one open model. NVIDIA open sourced the checkpoints, training scripts, deployment tools, and datasets. The Cosmos 3 release targets robotics, autonomous vehicles, and warehouse monitoring teams. NVIDIA Cosmos 3 Physical AI systems must understand the world before acting in it. Robots and vehicles need to perceive, predict, and then act. Earlier Cosmos releases split these jobs across separate models. Cosmos 3 unifies them with a Mixture-of-Transformers (MoT) architecture. The architecture is built around two towers. The reasoner tower is a vision-language model (VLM). It interprets images, videos, and text using an autoregressive architecture. It understands motion, object interactions, and other physical context. NVIDIA team describes this tower as the model’s brain. The generator tower produces future observations and action sequences. It uses a diffusion-based process for physics-aware video and actions. These outputs are conditioned on the reasoner tower’s understanding. Information flows one way, from reasoner to generator. The reasoner can run alone. The generator always activates both towers for guided generation. A single model can therefore handle reasoning and generation together. https://developer.nvidia.com/blog/develop-physical-ai-reasoning-world-and-action-models-with-nvidia-cosmos-3 The Model Family NVIDIA team describes three model scales: Edge, Nano, and Super. Each uses the dual-tower Mixture-of-Transformers design. The two towers are initialized from pre-trained Qwen3-VL weights. That roughly doubles the parameter count of the backbone transformer. Cosmos3-Nano is a 16B model built on a dense 8B transformer. It adapts the Qwen3-VL 8B architecture. Nano targets efficient inference on workstation GPUs. It runs on hardware like the NVIDIA RTX PRO 6000. That suits real-time robotics and on-device physical AI. Cosmos3-Super is a 64B model built on a dense 32B transformer. It adapts the Qwen3-VL 32B architecture. Super targets datacenter GPUs, including NVIDIA Hopper and Blackwell. It fits large-scale synthetic data generation and advanced reasoning. This release ships Nano and Super, along with task-specific variants. These include Super Text2Image, Super Image2Video, and Nano-Policy-DROID. How the Unified Design Works Both towers share one transformer architecture and a joint attention operator. They use a 3D multimodal rotary position embedding (mRoPE). mRoPE aligns video, audio, and action tokens on one temporal axis. In Reasoner Mode, tokens pass through causal self-attention. This enables next-token prediction for perception, planning, and reasoning. In Generator Mode, noisy tokens are denoised through full attention. The autoregressive tokens are never updated by the diffusion tokens. The model treats action as a core modality with dedicated action tokens. Supported inputs include text, image, video, and JSON action arrays. Outputs include images, video, synchronized sound, action states, and text. The reasoner follows Qwen3-VL-compatible message conventions for vision inputs. Generation supports 256p, 480p, and 720p resolution tiers. Frame counts range from 5 to 300, defaulting to 189. That equals about 7.9 seconds of video at 24 FPS. Sound is generated as stereo AAC at 48 kHz. Action conditioning spans camera, vehicle, egocentric, single-arm, dual-arm, and humanoid embodiments. Each embodiment uses a fixed action dimension, such as 9D for cameras. The Benchmark Case NVIDIA team evaluated Cosmos 3 across reasoning and generation suites. On reasoning, Super and Nano lead VANTAGE-Bench at their respective tiers. VANTAGE-Bench tests VLMs on real-world fixed-camera footage. It covers warehouses, transportation, and smart spaces. Cosmos 3 also tops the Traffic Anomaly Reasoning (TAR) leaderboard. TAR is the official leaderboard for AI City Challenge 2026 Track 3. On generation, NVIDIA reports open-source state-of-the-art results. Cosmos 3 is the open-source SOTA on R-Bench. It also leads PAI-Bench, Physics-IQ, and RoboLab on public leaderboards. On Artificial Analysis, it leads two open-source leaderboards. These cover text-to-image and image-to-video without audio. NVIDIA team also introduced its Cosmos Human Evaluation framework, called HUE. HUE decomposes each generated video into yes/no fact questions. It scores four dimensions across seven physical AI domains. The dimensions are semantic alignment, physical laws, geometric reasoning, and visual integrity. A VLM pipeline drafts the questions, and human experts refine them. Marktechpost’s Visual Explainer marktechpost@guide ~ /nvidia/cosmos-3 01 / 09 DEVELOPER GUIDE · PHYSICAL AI NVIDIA Cosmos 3 Open omnimodal world models for physical AI. Released May 31, 2026. One model for physical reasoning, world generation, and action generation. Mixture-of-Transformers Open weights OpenMDW-1.1 Use ← → or swipe to navigate 01 · WHAT IT IS A unified model for understanding and generation Cosmos 3 is a family of omnimodal world models for physical AI. Earlier Cosmos releases split jobs across separate models. Cosmos 3 unifies them in a single open model. Physical reasoning over images, video, and text. World generation of physics-aware video and sound. Action generation for robots and autonomous systems. Subsumes VLMs, video generators, world simulators, and world-action models. 02 · ARCHITECTURE Two towers, one transformer REASONER TOWER An autoregressive vision-language model (VLM). It interprets motion, object interactions, and physical context. NVIDIA calls it the model’s brain. GENERATOR TOWER A diffusion-based path for physics-aware video and actions. It is conditioned on the reasoner’s understanding. Information flows one way, reasoner → generator. Both towers share a 3D multimodal RoPE (mRoPE). 03 · MODEL FAMILY Pick a size for your hardware Cosmos3-Nano 16B total (dense 8B, Qwen3-VL 8B). Workstation GPUs like RTX PRO 6000. Real-time robotics. Cosmos3-Super 64B total (dense 32B, Qwen3-VL 32B). Datacenter Hopper and Blackwell GPUs. Large-scale SDG. Cosmos3-Edge 4B total (dense 2B). On-device scale. Planned for a later release. Plus variants: Super-Text2Image, Super-Image2Video, and Nano-Policy-DROID. 04 · MODALITIES Inputs, outputs, and generation settings Inputs: text, image, video, and JSON action arrays. Outputs: image, video, synchronized sound, action states, text. Resolution: 256p, 480p, 720p. Sound: stereo AAC at 48 kHz. Length: 5 to 300 frames; default 189 (about 7.9s at 24 FPS). Embodiments: camera, vehicle, egocentric, single-arm, dual-arm, humanoid. 05 · BENCHMARKS What NVIDIA reports REASONING Nano and Super lead VANTAGE-Bench at their tiers. Cosmos 3 tops TAR, the AI City Challenge 2026 Track 3 leaderboard. GENERATION Open-source SOTA on R-Bench. Leads PAI-Bench, Physics-IQ, and RoboLab. Top open-source on Artificial Analysis text-to-image and image-to-video. HUE evaluates videos with yes/no fact checks across four dimensions and seven domains. 06 · OPEN RELEASE Everything ships open Checkpoints for Nano, Super, and task-specific variants. Six SDG datasets: robotics, physics, spatial reasoning, human motion, driving, warehouses. Training recipes: SFT plus action post-training. Action modes: forward dynamics, inverse dynamics, and policy generation. License: OpenMDW-1.1. 07 · DEPLOYMENT Run it in production NIM microservices: Reasoner NIM available now; Generator NIM later. Quantization: BF16, FP8, and NVFP4. NVFP4 gives up to 2x speedup. Serving: the Reasoner NIM stack is built on vLLM. Efficient Video Sampling (EVS): prunes redundant video tokens at inference. Use Diffusers and Transformers for research; vLLM-Omni and vLLM for serving. 08 · LIMITATIONS & START Know the caveats, then build Outputs can show temporal inconsistency, unstable motion, object morphing, i
Related
相關文章

AI預測不了“佛得角”
AI預測模型在世界盃足球賽預測中集體失準,特別是對非洲隊伍「佛得角」的表現完全錯估,凸顯大模型在面臨動態不確定性與非主流聯賽數據不足時的脆弱性。這場預測翻車事件引發外界對AI可信度的質疑,也促使科技公司反思如何修正模型,導入即時動態資訊以提升預測準確度。

智能家居終於“智能”了!有記憶、能認人的“賈維斯”,小米先交卷了
{"id":"bfc7e789-db52-4597-89dc-85a30161bd27","object":"response","model":"deepseek-v4-flash","output":[],"stop_reason":"max_output_tokens","usage":{"input_tokens":158,"output_tokens":1400,"total_to...

AI 讓獨立遊戲更容易做出來,也更容易死在 Steam 裡
AI 降低了獨立遊戲的生產門檻,也放大了 Steam 供給過剩和玩家信任危機。獨立遊戲的競爭,正在從“能不能做出來”,轉向“能不能被看見、被相信、被持續選擇”。當工具讓內容越來越容易生成,真正稀缺的反而是人的表達、真實反饋、發行篩選與社區信任。

全球首個 AI 藝術博物館:谷歌協力打造,生成 12 億像素超現實畫面
谷歌昨日(6 月 18 日)發佈博文,宣佈攜手藝術家 Refik Anadol,在洛杉磯打造全球首個 AI 藝術博物館 Dataland,將於明日(6 月 20 日)開館。

八部門聯合發文力推“人工智能 + 消費”,擴大 AI 手機電腦及智能網聯汽車消費
商務部等八部門聯合印發《關於加快“人工智能 + 消費”發展的實施意見》,提出 5 方面 17 條舉措,旨在擴大智能產品消費、賦能服務消費、創新消費場景。政策將推動人工智能與消費深度融合,促進 AI 進千家萬戶。#人工智能消費新政##AI 手機電腦##智能網聯汽車#

魔法原子牽手萬機易租,全棧產品入駐2.0平臺共建租賃生態
這篇消息聚焦「魔法原子牽手萬機易租,全棧產品入駐2.0平臺共建租賃生態」。原始導語提到:全系產品入駐萬機易租2.0 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。