NVIDIA AI 推出 Dynamo Snapshot:基於 CRIU 的 Kubernetes 上 AI 推論快速啟動系統
重點摘要
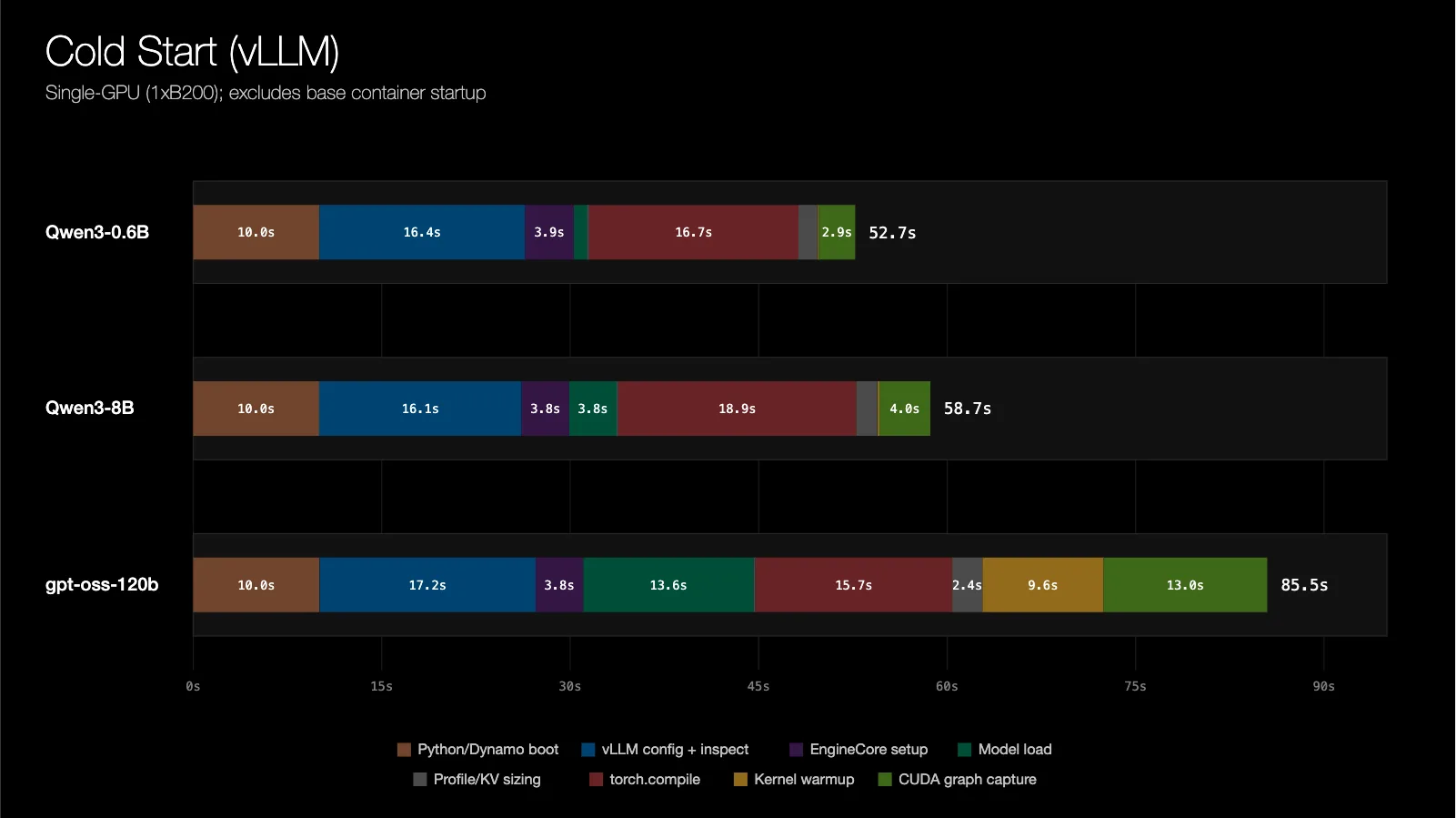
在生產環境的推論部署中,需求會隨時間波動,需要推論副本能彈性擴展。在 Kubernetes 上冷啟動推論工作負載可能耗費數分鐘,期間 GPU 雖已分配卻處於閒置狀態,既無法產生 token 也無法服務任何請求。「冷啟動」指的是模型伺服器在提供任何請求前必須完成的一連串程序:拉取容器映像檔、將模型權重載入 GPU 記憶體、預熱 CUDA 核心、編譯或捕捉 CUDA 圖形,以及向服務探索層註冊。此延遲在流量暴增時容易導致服務水準協議(SLA)違規,因為系統無法快速擴展以應付突增的需求。單 GPU vLLM(v0.20.0)工作負載的冷啟動延遲可分為三個階段:
In production inference deployments, demand fluctuates over time, requiring inference replicas to scale elastically. Cold-starting inference workloads on Kubernetes can take several minutes. During that time, GPUs are allocated but idle, generating no tokens and serving no requests. ‘Cold start’ means the full sequence a model server must complete before serving any request: pulling the container image, loading model weights into GPU memory, warming up CUDA kernels, compiling or capturing CUDA graphs, and registering with the service discovery layer. This delay increases the risk of SLA violations during traffic spikes, as the system cannot scale quickly enough to absorb sudden increases in demand. The cold-start latency for a single-GPU vLLM (v0.20.0) workload breaks into three segments: container/image pull, engine initialization (weight loading, kernel warmup, graph compilation), and distributed runtime startup. To address this, NVIDIA’s AI research team has introduced NVIDIA Dynamo Snapshot: a checkpoint/restore approach for AI inference workloads on Kubernetes. https://developer.nvidia.com/blog/nvidia-dynamo-snapshot-fast-startup-for-inference-workloads-on-kubernetes/?linkId=100000423964029 What is CRIU and cuda-checkpoint? A running inference worker’s checkpointable state has two components. Device state (GPU-side) includes CUDA contexts, streams, device memory, and virtual address mappings — this is not visible to the host. To serialize it, cuda-checkpoint uses the checkpointing capability of the CUDA driver to dump the device state to CPU memory of the process owning each CUDA context. Host state (CPU-side) includes CPU memory, threads, file descriptors, and namespaces. CRIU (Checkpoint/Restore in Userspace) walks the Linux kernel’s bookkeeping and serializes the process tree’s state to disk. When checkpointing, the two tools run in order: cuda-checkpoint dumps all device state into CPU memory first, then CRIU dumps all host-side process tree state to a folder in storage. When restoring on the same or a different node: CRIU restores the process tree from distributed storage such as NFS or SMB first, then cuda-checkpoint restores the GPU state from what is now in CPU memory onto the new GPUs. CRIU is fundamentally a freeze-and-thaw mechanism. When a process is restored, execution resumes at the exact instruction where it was checkpointed, completely unaware that checkpointing or restoration occurred. Because of this, any coordination required before checkpointing such as quiescing the workload or after restoration such as re-establishing external state — must be handled externally through an orchestrator or workload-specific hooks. How Dynamo Snapshot Works on Kubernetes In Kubernetes, workloads run inside containers inside pods. Because CRIU checkpoints contain references to the container’s writable filesystem layer, checkpointing is done at the container level so the process tree state and filesystem travel together. NVIDIA provides a privileged DaemonSet, snapshot-agent, installable through a Helm chart. An agent runs on every node and handles checkpoint and restore for runc-managed containers without requiring modifications to runc itself. On checkpoint, the agent waits for the workload’s readiness probe, invokes cuda-checkpoint and CRIU from the host side, and writes the artifact to shared storage. The workload may have created or deleted files local to the container (the overlay filesystem), which the agent also checkpoints after the CRIU stage. On restore, the agent launches a lightweight placeholder pod, restores the overlay filesystem, and restores the CRIU/CUDA checkpoint into its namespaces. Each agent operates independently on its local node, allowing checkpoints and restores to parallelize naturally across the cluster. This DaemonSet approach was chosen over Kubernetes native checkpoint/restore support in runc for three reasons: it is fully portable without depending on cloud-provider feature gates, it gives tighter control over CRIU for performance tuning, and it allows checkpoint artifacts to live in flexible storage backends rather than being embedded into OCI images. Quiesce/resume hooks: A Dynamo inference worker initializes in two ordered phases. First, engine initialization: communicators are initialized, weights are loaded, kernels are warmed up, and CUDA graphs are compiled. The worker is fully warm at this point but not yet discoverable outside its pod. Second, distributed runtime startup: the worker connects to the Dynamo control plane and registers with the discovery backend. Open TCP connections to the control plane exist from this point onward. If checkpoint were taken after distributed runtime startup, there would be active TCP connections that CRIU cannot capture. The solution is quiesce/resume hooks: the worker writes a ‘ready for checkpoint’ signal file after engine initialization but before distributed runtime startup. The worker then enters a polling loop waiting for a ‘restore complete’ signal file while the snapshot agent checkpoints it externally. Because CRIU restores execution at the exact instruction where checkpointing occurred, the worker resumes directly inside the polling loop, detects the signal file, and proceeds with distributed runtime initialization without requiring additional synchronization. The quiesce/resume pattern is also important for multi-GPU and multi-node checkpoints (planned for a future release): outbound TCP connections used for RPC cannot be checkpointed in an established state because the pod IP changes between checkpoint and restore, and RDMA registrations and NIC state need to be recreated post-restore. Optimization 1: KV Cache Unmap and Release After measuring peak GPU memory usage while weights, CUDA graphs, and other buffers are allocated, inference engines allocate the remaining GPU memory as a large KV cache buffer. Since the checkpoint is taken before the replica has served any requests, this KV cache buffer does not need to be checkpointed at all. However, its virtual address must remain stable because it is baked into the CUDA graph. The solution is to allocate the KV cache via the CUDA Virtual Memory Management API (cuMemCreate and cuMemMap), then free the underlying physical allocation with cuMemUnmap and cuMemRelease — but not cuMemAddressFree. This keeps the virtual address range intact while releasing the physical memory. This functionality is natively available in vLLM via sleep() and wake_up() and in SGLang via torch_memory_saver. For Qwen3-0.6B on a B200, this reduces the total artifact size from ~190 GiB to ~6 GiB. The wins are most pronounced for large KV cache sizes — that is, smaller model weights relative to GPU size. Optimization 2: Speeding Up CRIU Memory Restore Even after the artifact is smaller, upstream CRIU restore time remains a bottleneck. For larger models, restore time actually exceeds cold-start time, which negates the benefit of checkpointing. Note: The CRIU optimizations described below are not yet shipped as part of Dynamo Snapshot. They may be available once merged into upstream CRIU. 2.1 — Parallel memfd restore: vLLM’s sleep()/wake_up() path and SGLang’s torch_memory_saver move weight-tagged GPU allocations into pinned CPU shadow buffers. CUDA backs these allocations with shared anonymous memory, pinned through the NVIDIA driver. Inside the Linux kernel, these appear as memfds: anonymous, RAM-backed files mapped with MAP_SHARED. For gpt-oss-120b, these buffers consumed more than 120 GiB, split across many independent 2 GiB-or-smaller buffers. Upstream CRIU restores those buffers serially. The modified CRIU enumerates all unique shmem-backed objects, then uses a thread pool to restore them in parallel, allowing restore to use available storage bandwidth and CPU parallelism. 2.2 — Linux native AIO for anonymous memory: In upstream CRIU, the memory restore path is a synchronous preadv loop with exactly one read in flight at any moment, leav
Related
相關文章

Edge AI Daily 早報(6月19日)
AI Engineer World's Fair 2026規模再創新高,標誌AI工程從幕後走向舞臺中央。行業面臨結構性調整:楊立昆警示OpenAI年虧210億美元揭示商業模式脆弱性,Transformer之父轉投OpenAI反映人才爭奪白熱化。Anthropic多線佈局——語音支持七種語言、加入碳清除聯盟、落子首爾辦事處,展現生態擴張野心。監管壓力加劇,意大利依據DMA調查蘋果iCloud,巴西開放iOS側載佣金降至5%,蘋果圍牆花園持續崩塌。

今天起,Claude Design要把設計師和程序員變成同一種人了
猝不及防!Anthropic深夜甩出Claude Design大更新,設計系統一鍵導入,代碼雙向同步,9大平臺一鍵導出。Anthropic設計師親自下場錄屏:AI跑了八輪自查,才敢把設計稿給你看。

OpenAI 成為 Rust 基金會白金會員,合計贊助 60 萬美元
OpenAI 正式成為 Rust 基金會白金會員,將提供總計 60 萬美元資金,用於支持 Rust 開源項目維護者及 Rust 創新實驗室等計劃。這標誌著 AI 巨頭對安全、高效系統編程語言的重視。 #OpenAI #Rust #開源

Claude Design 上線首周用戶破百萬,和 Claude Code 共享 AI 配額
Anthropic 今天(6 月 18 日)發佈公告,在宣佈 Claude Design 上線首周用戶規模突破 100 萬後,進一步強化和 Claude Code 的雙向聯動,實現從設計到編程的無縫工作流。
谷歌時隔6年再發智能音箱,Gemini上桌,售價不到700元
智東西 編譯 | 劉煜 編輯 | 陳駿達 智東西6月18日消息,谷歌昨日宣佈,其首款搭載居家版Gemini語音助手的智能音箱(Google Home Speaker)已開啟預售,將於當地時間6月25日正式上市,售價為99.99美元(約合人民幣677.03元)。在此之前,谷歌已有6年沒有推出過獨立智能音箱產品。 谷歌這款智能音箱外觀近似球形,風格類似亞馬遜新一代Echo音箱與蘋果舊款音箱HomePod Mini。 ▲谷歌智能音箱(圖源:谷歌官網) 使用音箱時,用戶只需通過口令“Hey Google”或“OK Google”喚醒Gemini,就可以繼續下達相應指令。這與谷歌舊款音箱、智能顯示屏等喚醒語音助手的方式相同。此外,用戶只要按照日常說話習慣下達命令,Gemini便能理解用戶意圖,相比之前大大提升溝通效率。 一、加強短時對話記憶,會員可與Gemini不限次數對話 谷歌此次推出的全新音箱升級諸多功能。其中,音箱搭載的Gemini語音助手擁有10款全新擬人化語音音色,用戶可以根據喜好自行選擇聲線。音箱還可支持用戶一次性下達多條語音指令,即使指令未能說對、說完整,用戶中途改口Gemini也能識別。 Gemini還具備多鏈路推理能力,落地到實際生活場景中比較實用。例如,用戶問:“我支持的足球隊下場比賽天氣如何?”Gemini收到指令後,會自動查詢賽事時間、舉辦地點,同時匹配相應時段天氣,再給出答覆。 同時,Gemini加強了短時對話記憶,能承接上下文實現連續對話功能。即使用戶連續追問、甚至串聯多項任務、不重複交代前置條件,該語音助手也能實現來回連貫交流。 ▲谷歌Gemini對話場景(圖源:谷歌官網) 不僅如此,Gemini搭配的連續對話功能,能讓應答後的音箱麥克風保持短暫收音,用戶無需重複喊“OK Google”就能繼續提問。該功能現已全面支持所有Gemini原生適配的語言,包括

微軟,考慮接入DeepSeek
這篇消息聚焦「微軟,考慮接入DeepSeek」。原始導語提到:Copilot Cowork轉為按量計費。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。