MEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM Parameters
重點摘要
Large language models become static after pretraining. Their knowledge does not update as the world changes. Retraining a full LLM is too expensive at modern scales. Fine-tuning risks degrading previously learned knowledge. Retrieval-augmented generation (RAG) struggles when answers require reasoning across many documents. A team of researchers from the National University of Singapore, MIT CSAIL, A*STAR, and the Singapore-MIT Alliance for Research and Technology (SMART) proposes a new approach called MEMO (Memory as a Model). What Problem Does MEMO Solve? Existing methods for integrating new knowledge into LLMs fall into three categories. Non-parametric methods like RAG retrieve documents at inference time. They are sensitive to retrieval noise and struggle with cross-document reasoning.
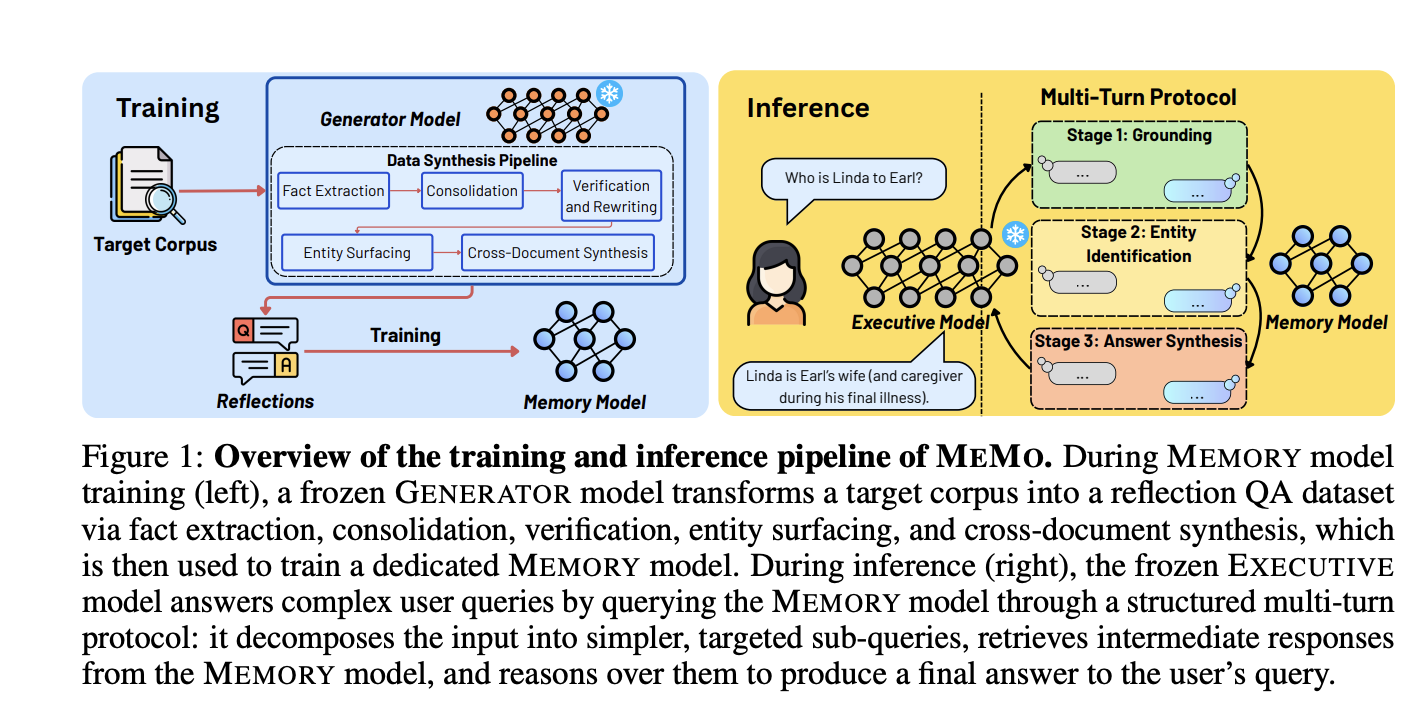
Large language models become static after pretraining. Their knowledge does not update as the world changes. Retraining a full LLM is too expensive at modern scales. Fine-tuning risks degrading previously learned knowledge. Retrieval-augmented generation (RAG) struggles when answers require reasoning across many documents. A team of researchers from the National University of Singapore, MIT CSAIL, A*STAR, and the Singapore-MIT Alliance for Research and Technology (SMART) proposes a new approach called MEMO (Memory as a Model). What Problem Does MEMO Solve? Existing methods for integrating new knowledge into LLMs fall into three categories. Non-parametric methods like RAG retrieve documents at inference time. They are sensitive to retrieval noise and struggle with cross-document reasoning. Parametric methods such as continual pretraining or supervised fine-tuning internalize knowledge into model weights. They are computationally expensive and cause catastrophic forgetting, where new training degrades previously acquired knowledge. Latent memory methods compress knowledge into soft tokens. These representations are tightly bound to the model that produced them — a limitation the research team calls representation coupling which limits transferability across LLMs. MEMORY as a Separate Model MEMO separates memory from reasoning. The MEMORY model is a small, dedicated language model trained to internalize knowledge from a target corpus. The EXECUTIVE model is the main LLM — frozen and queried only through its standard input-output interface. In experiments, the MEMORY model is Qwen2.5-14B-Instruct. The EXECUTIVE model is either Qwen2.5-32B-Instruct or Gemini-3-Flash, a proprietary closed-source model. Because MEMO treats the EXECUTIVE model as a black box, it does not require weight access or output logits. https://arxiv.org/pdf/2605.15156 How the MEMORY Model is Trained Training begins with a five-step data synthesis pipeline guided by a GENERATOR model — Qwen2.5-32B-Instruct in experiments. The pipeline converts a raw document corpus into a reflection QA dataset: question-answer pairs that represent corpus knowledge under diverse query variations. The five steps are: Fact extraction — direct extraction of explicitly stated facts, and indirect extraction of inferred information, run in parallel per document chunk. Consolidation — QA pairs sharing a common context (entity, time period, relationship) are merged into multi-fact pairs. Verification and rewriting — each QA pair is checked for self-containment. Pairs with unresolved pronouns or implicit references are rewritten using the source chunk or discarded. Entity surfacing — QA pairs are generated where questions encode entity attributes and relationships, and answers reveal entity identities. This targets the reversal curse, where models trained on “A is B” fail to infer “B is A.” Cross-document synthesis — the GENERATOR model constructs QA pairs spanning multiple documents. It identifies two types of cross-document connections: converging clues (multiple documents about the same entity) and parallel properties (different entities sharing a common attribute or role). Step-5 is the most critical component. A leave-one-out ablation shows that removing it drops accuracy from 24.00% to 6.37% on NarrativeQA. It is also the dominant source of training pairs in the final dataset. The MEMORY model is then trained via supervised fine-tuning (SFT). The loss is computed over answer tokens only. Source documents are never provided at inference. The model must answer from internalized parametric knowledge. Inference: The Structured Multi-Turn Protocol At inference, the EXECUTIVE model queries the MEMORY model through a structured multi-turn protocol with three sequential stages. Stage 1: Grounding. The EXECUTIVE model decomposes the query into atomic sub-questions. Each targets a single identifying constraint. The MEMORY model answers each independently. Stage 2: Entity identification. Using the grounding responses, the EXECUTIVE model issues targeted follow-up sub-queries. It iteratively narrows down candidate entities until one is confirmed or the stage budget runs out. Stage 3: Answer seeking and synthesis. Conditioned on the identified entity, the EXECUTIVE model queries the MEMORY model for supporting facts. It then synthesizes all retrieved responses into a final answer. The MEMORY model’s responses are compact natural-language snippets. Their length is independent of corpus size, so retrieval cost does not scale with the number of documents. This contrasts with RAG, where inference cost grows with the corpus. Experimental Results MEMO is evaluated on three benchmarks: BrowseComp-Plus (multi-hop deep-research), NarrativeQA (discourse understanding over books and movie scripts), and MuSiQue (2–4 hop reasoning over Wikipedia paragraphs). Baselines include BM25, NV-Embed-V2, HippoRAG2, and Cartridges. Cartridges requires white-box access to the EXECUTIVE model and scored 0.00% on BrowseComp-Plus and 3.75% on NarrativeQA. On NarrativeQA with Gemini-3-Flash, MEMO achieves 53.58%. HippoRAG2 reaches 23.21% on the same setup. On MuSiQue, MEMO achieves 60.20% against HippoRAG2’s 57.00%. On BrowseComp-Plus, MEMO achieves 66.67% against HippoRAG2’s 66.33%. With Qwen2.5-32B-Instruct as EXECUTIVE model, MEMO achieves 54.22% on BrowseComp-Plus and 48.30% on MuSiQue. Switching to Gemini-3-Flash yields gains of 12.45%, 26.73%, and 11.90% on the three benchmarks. The MEMORY model is not retrained when the EXECUTIVE model changes. Robustness to retrieval noise: The research team evaluates performance when distractor documents are added to the corpus. NV-Embed-V2 and HippoRAG2 drop by up to 6.22% on BrowseComp-Plus when one negative document is added per evidence document. MEMO’s accuracy on the same benchmark changes by +0.55% — within one standard deviation. MEMORY model architecture robustness: The research team also tests three MEMORY model families at similar parameter scale: Qwen2.5-1.5B-Instruct, Gemma3-1B-IT, and LFM2.5-1.2B-Instruct (a hybrid state-space and transformer architecture). Performance is largely consistent across all three, indicating the framework is not sensitive to the specific pretraining lineage of MEMORY model. Continual Knowledge Integration via Model Merging MEMO supports incremental knowledge updates through model merging. When a new corpus arrives, a separate MEMORY model is trained on it independently. Its task vector — the parameter difference from the base model — is then merged with the existing MEMORY model in parameter space. The research team test this on NarrativeQA using TIES merging (ρ=0.3). For K=2 corpora, merging accumulates 48 GPU-hours versus 72 GPU-hours for full retraining — a 33% reduction. At K=10, merging scales as Θ(K) while full retraining scales as Θ(K²), yielding a 5.5× saving (240 vs. 1,320 GPU-hours). The merged MEMORY model trails full retraining by 11.04% under Qwen2.5-32B-Instruct (15.81% vs. 26.85%). It trails by 19.11% under Gemini-3-Flash (34.47% vs. 53.58%). Despite this gap, it outperforms all retrieval baselines on NarrativeQA. Marktechpost’s Visual Explainer #mex2-wrap{all:unset;display:block!important;font-family:'IBM Plex Sans',system-ui,sans-serif!important;background:#080808!important;border-radius:6px!important;overflow:hidden!important;max-width:800px!important;margin:0 auto!important} #mex2-wrap *{box-sizing:border-box!important;margin:0!important;padding:0!important} #mex2-wrap .mx-bar{display:flex!important;align-items:center!important;justify-content:space-between!important;padding:14px 24px!important;border-bottom:1px solid #161616!important} #mex2-wrap .mx-bar-label{font-size:9px!important;letter-spacing:0.2em!important;text-transform:uppercase!important;color:#3a3a3a!important;font-family:'IBM Plex Mono',monospace!important} #mex2-wrap .mx-bar-title{font-size:11px!important;font-weight:600!important;color:#555!important} #mex2-wrap .mx-overflow{o
Related
相關文章

Edge AI Daily 早報(6月19日)
AI Engineer World's Fair 2026規模再創新高,標誌AI工程從幕後走向舞臺中央。行業面臨結構性調整:楊立昆警示OpenAI年虧210億美元揭示商業模式脆弱性,Transformer之父轉投OpenAI反映人才爭奪白熱化。Anthropic多線佈局——語音支持七種語言、加入碳清除聯盟、落子首爾辦事處,展現生態擴張野心。監管壓力加劇,意大利依據DMA調查蘋果iCloud,巴西開放iOS側載佣金降至5%,蘋果圍牆花園持續崩塌。

今天起,Claude Design要把設計師和程序員變成同一種人了
猝不及防!Anthropic深夜甩出Claude Design大更新,設計系統一鍵導入,代碼雙向同步,9大平臺一鍵導出。Anthropic設計師親自下場錄屏:AI跑了八輪自查,才敢把設計稿給你看。

OpenAI 成為 Rust 基金會白金會員,合計贊助 60 萬美元
OpenAI 正式成為 Rust 基金會白金會員,將提供總計 60 萬美元資金,用於支持 Rust 開源項目維護者及 Rust 創新實驗室等計劃。這標誌著 AI 巨頭對安全、高效系統編程語言的重視。 #OpenAI #Rust #開源

Claude Design 上線首周用戶破百萬,和 Claude Code 共享 AI 配額
Anthropic 今天(6 月 18 日)發佈公告,在宣佈 Claude Design 上線首周用戶規模突破 100 萬後,進一步強化和 Claude Code 的雙向聯動,實現從設計到編程的無縫工作流。
谷歌時隔6年再發智能音箱,Gemini上桌,售價不到700元
智東西 編譯 | 劉煜 編輯 | 陳駿達 智東西6月18日消息,谷歌昨日宣佈,其首款搭載居家版Gemini語音助手的智能音箱(Google Home Speaker)已開啟預售,將於當地時間6月25日正式上市,售價為99.99美元(約合人民幣677.03元)。在此之前,谷歌已有6年沒有推出過獨立智能音箱產品。 谷歌這款智能音箱外觀近似球形,風格類似亞馬遜新一代Echo音箱與蘋果舊款音箱HomePod Mini。 ▲谷歌智能音箱(圖源:谷歌官網) 使用音箱時,用戶只需通過口令“Hey Google”或“OK Google”喚醒Gemini,就可以繼續下達相應指令。這與谷歌舊款音箱、智能顯示屏等喚醒語音助手的方式相同。此外,用戶只要按照日常說話習慣下達命令,Gemini便能理解用戶意圖,相比之前大大提升溝通效率。 一、加強短時對話記憶,會員可與Gemini不限次數對話 谷歌此次推出的全新音箱升級諸多功能。其中,音箱搭載的Gemini語音助手擁有10款全新擬人化語音音色,用戶可以根據喜好自行選擇聲線。音箱還可支持用戶一次性下達多條語音指令,即使指令未能說對、說完整,用戶中途改口Gemini也能識別。 Gemini還具備多鏈路推理能力,落地到實際生活場景中比較實用。例如,用戶問:“我支持的足球隊下場比賽天氣如何?”Gemini收到指令後,會自動查詢賽事時間、舉辦地點,同時匹配相應時段天氣,再給出答覆。 同時,Gemini加強了短時對話記憶,能承接上下文實現連續對話功能。即使用戶連續追問、甚至串聯多項任務、不重複交代前置條件,該語音助手也能實現來回連貫交流。 ▲谷歌Gemini對話場景(圖源:谷歌官網) 不僅如此,Gemini搭配的連續對話功能,能讓應答後的音箱麥克風保持短暫收音,用戶無需重複喊“OK Google”就能繼續提問。該功能現已全面支持所有Gemini原生適配的語言,包括

微軟,考慮接入DeepSeek
這篇消息聚焦「微軟,考慮接入DeepSeek」。原始導語提到:Copilot Cowork轉為按量計費。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。