Miso Labs 推出 MisoTTS:具備 80 億參數、開放權重的情感文字轉語音模型
重點摘要
Miso Labs 發布 MisoTTS,這是一款開放權重的 80 億參數文字轉語音模型。它能根據文字與音訊脈絡生成富有表現力的語音。模型採用殘差向量量化(RVQ)技術擴展聲音範圍,避免在固定參數量下擴充單一扁平詞彙。MisoTTS 是一個 80 億參數的文字轉對話 RVQ Transformer,靈感來自 Sesame CSM 架構,結合 Llama 3.2 風格的主幹與較小的音訊解碼器,可從文字與選擇性音訊脈絡生成 Mimi 音訊編碼。模型同時以文字與先前音訊為條件,後者可讓它回應說話者的語調。其文字詞彙量為 128,256 個標記,並包含 32 組音訊碼簿。Mimi 為音訊分詞器,最大序列長度為……
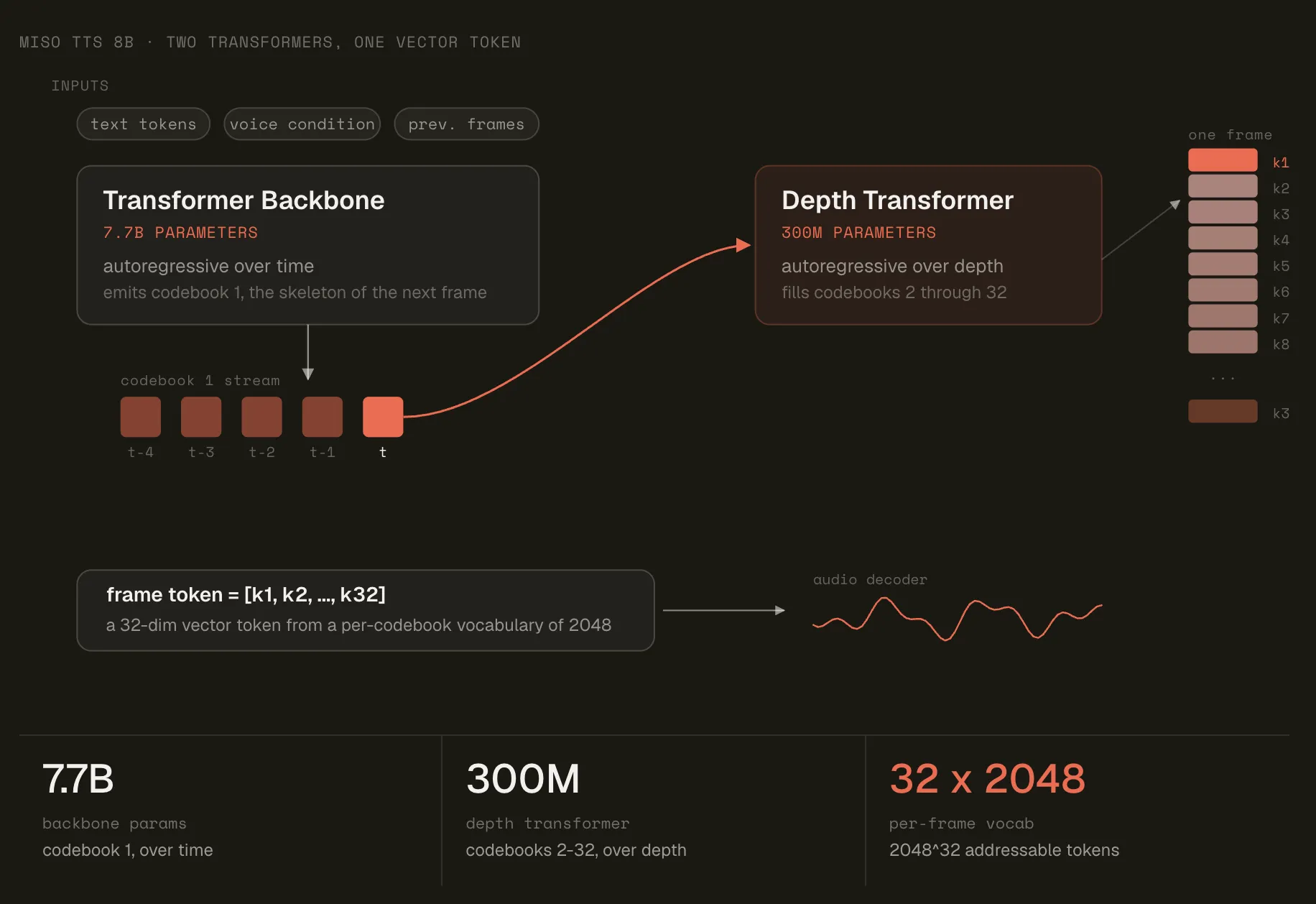
Miso Labs has released MisoTTS, an open-weights 8-billion-parameter text-to-speech model. It generates expressive speech from both text and audio context. The model uses residual vector quantization (RVQ) to widen its sonic range. This avoids scaling a single flat vocabulary while keeping parameter count fixed. What is MisoTTS MisoTTS is an 8B-parameter text-to-dialogue RVQ Transformer. It is inspired by the Sesame CSM architecture. It pairs a Llama 3.2-style backbone with a smaller audio decoder. It generates Mimi audio codes from text and optional audio context. The model conditions on both text and prior audio. That second input lets it respond to the speaker’s tone. The text vocabulary is 128,256 tokens, and there are 32 audio codebooks. Mimi is the audio tokenizer, and max sequence length is 2,048. Default inference runs in torch.bfloat16. Miso Labs claims 110ms latency. It lists ElevenLabs at 700ms and Sesame at 300ms. The Vocabulary Size Problem Standard transformers generate from a fixed vocabulary of discrete tokens. That works when a small vocabulary covers the target space. Human speech does not fit that assumption. It varies across pitch, rhythm, emphasis, emotion, and accent. Expanding the audio vocabulary is the obvious fix. But larger vocabularies need more parameters in a standard transformer. Each token must be represented and predicted by the model. Miso Labs calls this the vocabulary size problem. The second issue is conditioning. Most TTS models condition only on text. They ignore the interlocutor’s tone. Miso Labs argues this contributes to the “uncanny valley” effect. Residual Vector Quantization: The Core Idea MisoTTS addresses both problems with residual vector quantization (RVQ). Miso Labs traces RVQ to image-generation research and to Sesame’s CSM for audio. Instead of one token index, the model emits a vector of indices. Each audio token is 32 codebook indices over 2048-way codebooks. The model keeps a separate codebook for each position in the vector. To recover the sound, it sums the looked-up vectors. Each codebook adds another refinement to the signal. This is what makes the scaling work. Addressable vocabulary equals codebook size raised to the depth. Growing the depth adds no parameters to the model. So MisoTTS reaches about 204832, or roughly 10105 addressable tokens. Miso Labs notes naive scaling would require a far larger network. https://www.misolabs.ai/blog/miso-tts-8b The Two-Transformer Architecture The model splits into a backbone and a decoder. The backbone is a 7.7B-parameter transformer, autoregressive over time. It predicts the first codebook index and a final hidden state. A 300M-parameter decoder then runs autoregressively over depth. It predicts the remaining codebook indices, one position at a time. Each prediction conditions on the indices already chosen in the frame. The same 300M parameters are reused for every position. Embeddings follow the same logic. Text tokens use a single lookup. An audio token’s embedding is the sum of per-position codebook lookups. Interleaving text and audio lets the backbone use conversation history. That is how it carries context across turns. Strengths and Challenges Strengths: Open weights on day one, under a modified MIT license. RVQ scales the sonic range without scaling parameter count. Conditions on audio context, not text alone. Local deployment keeps sensitive audio data in-house. The architecture and math are documented in a public blog post. Challenges: Half-duplex only, with no turn-taking yet. The large model needs a capable CUDA GPU. API access is announced but not yet available. Latency and quality claims still need third-party testing. Marktechpost’s Visual Explainer @import url('https://fonts.googleapis.com/css2?family=Fraunces:opsz,[email protected],400;9..144,500;9..144,600&family=JetBrains+Mono:wght@400;600&display=swap'); #mtp-misotts-slider{ --paper:#F0EEE6; --surface:#FAF9F5; --ink:#141413; --muted:#6B6960; --accent:#D97757; --accent-dk:#BD5D3E; --line:#DED9CC; --line-soft:#E8E4D8; --serif:"Fraunces",Georgia,"Times New Roman",serif; --sans:-apple-system,BlinkMacSystemFont,"Segoe UI",Helvetica,Arial,sans-serif; --mono:"JetBrains Mono",ui-monospace,SFMono-Regular,Menlo,Consolas,monospace; max-width:860px!important; margin:28px auto!important; padding:0!important; background:var(--paper)!important; color:var(--ink)!important; border:1px solid var(--line)!important; border-radius:18px!important; box-shadow:0 1px 0 #fff inset, 0 18px 40px -28px rgba(20,20,19,.35)!important; font-family:var(--sans)!important; overflow:hidden!important; position:relative!important; -webkit-font-smoothing:antialiased; box-sizing:border-box!important; } #mtp-misotts-slider *{ box-sizing:border-box!important; } /* wpautop suppression */ #mtp-misotts-slider hr, #mtp-misotts-slider p:empty, #mtp-misotts-slider del, #mtp-misotts-slider s{ display:none!important; } /* ---- header bar ---- */ #mtp-misotts-slider .mtp-top{ display:flex!important; align-items:center!important; justify-content:space-between!important; padding:16px 26px!important; border-bottom:1px solid var(--line-soft)!important; background:var(--surface)!important; } #mtp-misotts-slider .mtp-brand{ font-family:var(--sans)!important; font-size:12px!important; letter-spacing:.14em!important; text-transform:uppercase!important; color:var(--ink)!important; font-weight:600!important; } #mtp-misotts-slider .mtp-brand b{ color:var(--accent)!important; } #mtp-misotts-slider .mtp-count{ font-family:var(--mono)!important; font-size:12px!important; color:var(--muted)!important; letter-spacing:.04em!important; } /* ---- viewport / track ---- */ #mtp-misotts-slider .mtp-view{ overflow:hidden!important; position:relative!important; } #mtp-misotts-slider .mtp-track{ display:flex!important; transition:transform .45s cubic-bezier(.4,.01,.2,1)!important; will-change:transform; } #mtp-misotts-slider .mtp-slide{ min-width:100%!important; padding:34px 44px 30px!important; min-height:474px!important; display:flex!important; flex-direction:column!important; justify-content:flex-start!important; } #mtp-misotts-slider .mtp-eyebrow{ font-family:var(--mono)!important; font-size:11.5px!important; letter-spacing:.16em!important; text-transform:uppercase!important; color:var(--accent-dk)!important; margin:0 0 14px!important; font-weight:600!important; } #mtp-misotts-slider h2.mtp-h{ font-family:var(--serif)!important; font-weight:500!important; color:var(--ink)!important; font-size:30px!important; line-height:1.16!important; margin:0 0 8px!important; letter-spacing:-.01em!important; } #mtp-misotts-slider .mtp-sub{ font-family:var(--sans)!important; font-size:15.5px!important; line-height:1.55!important; color:var(--muted)!important; margin:0 0 20px!important; max-width:62ch!important; } #mtp-misotts-slider .mtp-rule{ height:1px!important; width:54px!important; background:var(--accent)!important; border:0!important; margin:0 0 22px!important; display:block!important; border-radius:2px!important; } /* cover slide */ #mtp-misotts-slider .mtp-cover h2.mtp-h{ font-size:52px!important; margin-top:6px!important; } #mtp-misotts-slider .mtp-cover .mtp-sub{ font-size:18px!important; color:var(--ink)!important; } #mtp-misotts-slider .mtp-tags{ display:flex!important; flex-wrap:wrap!important; gap:8px!important; margin-top:24px!important; } #mtp-misotts-slider .mtp-chip{ font-family:var(--mono)!important; font-size:12px!important; color:var(--ink)!important; background:#fff!important; border:1px solid var(--line)!important; padding:6px 11px!important; border-radius:999px!important; } /* bullet lists */ #mtp-misotts-slider ul.mtp-list{ list-style:none!important; margin:4px 0 0!important; padding:0!important; } #mtp-misotts-slider ul.mtp-list li{ position:relative!important; padding:0 0 0 26px!important; margin:0 0 15px!important; font-family:var(--sans)!important; font-size:15.5px!important; line-height:1.5!important; color:var(--ink)!important; } #mtp-misotts-
Related
相關文章
Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are the first bidirectional members of the LFM family. They build on LFM2.5-350M-Base, released in March. The pair targets fast multilingual and cross-lingual search across 11 languages. Their footprint is small enough to run almost anywhere. Both are available now on Hugging Face under the LFM Open License v1.0. LFM2.5 Retrievers The two models share one backbone but represent text differently. LFM2.5-Embedding-350M is a dense bi-encoder. It turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index. LFM2.5-ColBERT-350M is a late-interaction model. It converts each token into a vector rather
Perplexity Launches Brain, a Self-Improving Memory System That Builds a Context Graph of an Agent’s Work and Learns Overnight
Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different path. Today, Perplexity launched Brain, a self-improving memory system for its agent product, Computer. Brain does not focus on remembering you. It remembers what the agent did. That reframes what memory in AI is for. What is Perplexity‘s Brain Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews that graph. It then teaches itself how to do the work better. The idea is straightforward. The more work you do, the more efficient Brain makes your Computer. Brain is rolling out today to Perplexity Max and Enterprise Max subscribers in Research Preview. Two Axes of AI Memory Perp

智譜新高,MiniMax承壓,“大模型雙雄”命運殊途
這篇消息聚焦「智譜新高,MiniMax承壓,“大模型雙雄”命運殊途」。原始導語提到:大模型在被市場重新定價 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

華為昇騰 0 Day 支持智譜 GLM-5.2 模型,提供全面推理優化
華為昇騰 AI 宣佈在智譜開源 GLM-5.2 大模型當天即完成深度推理優化。通過 MOE 大融合算子、通信計算融合、高併發調度等七項關鍵技術,顯著提升編程和長程任務的處理效率,現已支持 A3 系列產品部署。#AI 大模型# #國產算力#
企業AI轉型再添利器:青雲科技算力雲接入 MiniMax-M3 模型
企業AI落地面臨高效低成本難題。青雲科技旗下基石智算平臺接入國產開源大模型MiniMax-M3,提供新算力支持。MiniMax-M3以卓越上下文處理能力等三大核心技術見長,依託自研架構,助企業便捷部署AI業務。
阿里開源統一科學大模型 LOGOS,僅用五十六分之一參數超越微軟
阿里 ATH-Token Foundry 聯閤中國人民大學高瓴人工智能學院開源科學基礎模型 LOGOS。該模型採用統一科學語法與純序列建模範式,在六大科學任務上匹配或超越傳統專用方法。其中 LOGOS-1B 僅 1B 參數,即展現出極高效率,性能超越參數量達 8×7B 的微軟模型。