DiScoFormer:一個Transformer同時處理密度與分數,跨分佈適用
重點摘要
許多機器學習和科學問題都歸結為同一項任務:你有一組資料點,想要恢復它們所來自的分佈——哪些數值常見,哪些罕見。找出分佈意味著估計兩個量:分佈的密度,以及隨著維度增加更有用的分數。密度是直方圖的平滑版本——在點聚集處高,在點稀少處低。分數——對數密度的梯度——指向密度上升最快的方向:沿著分數方向移動一個點...
Back to Articles DiScoFormer: One transformer for density and score, across distributions Enterprise Article Published June 29, 2026 Upvote 4 Kyle Wiggers Ai2Comms Follow allenai 📄 Tech report: arxiv.org/abs/2511.05924 Many problems in machine learning and the sciences come down to the same task: you have a collection of data points and want to recover the distribution they came from—which values are common, and which are rare. Pinning down that distribution means estimating two quantities: the distribution's density and, more useful as dimensionality grows, its score. The density is the smooth version of a histogram—high where points cluster and low where they're scarce. The score—the gradient of the log-density—points in the direction the density rises fastest: move a point along the score and it heads toward a more probable region. Diffusion-based generative models (the technology behind AI image generators like Stable Diffusion and DALL-E) start from random noise and repeatedly follow the score, turning that noise into a realistic image. The same score drives Bayesian sampling and the particle simulations used to model systems such as plasma. Extracting the density and score from a finite sample is challenging, and today's tools force a trade-off between generalizability and accuracy. One classical approach, kernel density estimation (KDE), computes the density at any location from the data points around it: the closer and more numerous they are, the higher the density. It needs no training and applies to any distribution, but its accuracy falls off sharply as dimensionality grows. Alternatively, neural score-matching models trained to predict the score stay accurate even in high dimensions, but each needs to learn the distribution and must be retrained from scratch for another. We introduce a new solution called the DiScoFormer (Density and Score Transformer)—one model that, given a set of data points, estimates both the density and the score of the distribution in a single forward pass without retraining. Training a transformer for density and score estimation DiScoFormer maps an entire sample to the density and score of the distribution behind it using stacked layers of transformer blocks. The model utilizes cross-attention, which allows it to evaluate density and score at any point—not just where you have data. Score and density share a mathematical relationship: score is the gradient of the logarithm of density. We leverage this by having a shared backbone with two output heads, one for the density and one for the score. This coupling does more than save parameters. The score head has to match the gradient of the log-density head at every query, so any gap between them is a label-free consistency loss. We use this at inference—hold the context fixed, take a few gradient steps on that consistency loss, and DiScoFormer adapts itself to an out-of-distribution input on the spot, no ground-truth density or score required. There's a mathematical reason why the transformer architecture fits this task. Kernel density estimation has a single bandwidth—how far each point's influence reaches, fixed in advance and applied identically everywhere. Attention is a strict generalization of it: we analytically show that a single attention head's weights are nearly a Gaussian kernel over the data, so one cross-attention block can already reproduce KDE's density and score. From there the model goes further, learning several such scales at once and adapting them to the data. DiScoFormer doesn't discard the classical method for a black box but instead includes KDE as a special case and improves on it. What data did we use to train DiScoFormer? We relied on Gaussian Mixture Models for two primary reasons. Firstly, GMMs are universal density approximators—with enough components they match essentially any smooth distribution to arbitrarily small error. Secondly, GMMs have closed-form densities and scores, so we always have an exact target to supervise against. We employ both of these properties by drawing a new GMM for every batch, giving the model virtually unlimited examples of target distributions and supervising each against a given GMM's exact density and score. Performance Across the board, DiScoFormer beats KDE at both density and score estimation, and the gap widens exactly where KDE struggles. In 100 dimensions, it isn't close—against the best hand-tuned KDE, it cuts score error by about 6.5x and density error by more than 37x, and it keeps improving as you add samples, while KDE runs out of memory. It also travels far outside its training data, staying accurate on mixtures with more modes than it ever saw during training and on non-Gaussian shapes like the Laplace and Student-t. KDE's main advantage remains speed, especially when datasets are small. The part about DiScoFormer that we find most promising is that score estimation is a shared dependency across many fields, such as generative modeling, Bayesian inference, and scientific computing. A pretrained, plug-in estimator that stays accurate in high dimensions and removes the need to retrain per problem could cut that cost across all of them at once—one model, reused everywhere score and density show up. We encourage you to read our technical report for more details. More from this author Which tokens does a hybrid model predict better? 8 June 25, 2026 MolmoMotion: Language-guided 3D motion forecasting 10 June 17, 2026 Community EditPreview Upload images, audio, and videos by dragging in the text input, pasting, or clicking here. Tap or paste here to upload images Comment · Sign up or log in to comment Upvote 4
Related
相關文章

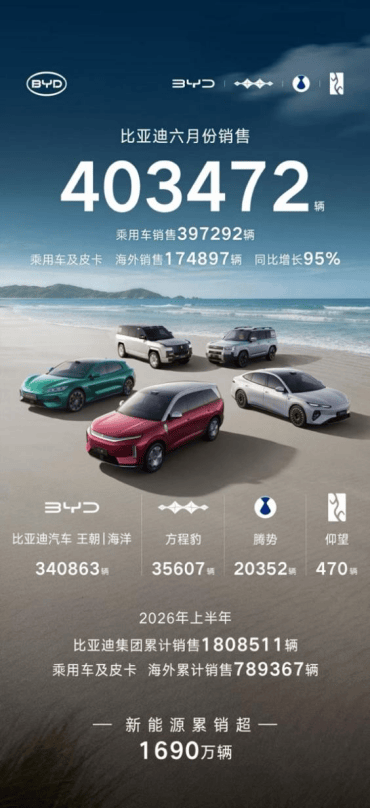
比亞迪6月銷量超40萬,年內銷量記錄再度刷新
### 比亞迪6月銷量突破40萬輛,年內記錄再次改寫 比亞迪在2024年6月交出亮眼成績單,單月銷售量正式跨越40萬輛大關,刷新今年以來的最高紀錄。這不僅延續了該品牌在新能源車市的強勢表現,也顯示其在供應鏈管理、產品布局與市場策略上持續進化。儘管官方未公布詳細車款與動力類型分布,但從整體規模來看,這項數字已足以讓比亞迪穩坐全球電動車銷量龍頭。


Java即將放棄Intel Mac:JDK 27起不再續命
Java 官方宣布將從 JDK 27 版本開始,正式停止對 Intel 架構 Mac 平台的支援。此舉反映了軟體生態正加速從 x86 轉向蘋果自研 M 系列晶片的 ARM 架構,開發者需提前因應硬體架構<pad><pad>遷徙。

一年吃掉一塊固態硬盤,Codex日誌bug被罵“劣質軟件”
微軟 Codex 因日誌記錄 Bug,會持續大量寫入數據,導致固態硬碟壽命快速耗盡,被用戶批評為「劣質軟體」。據稱此漏洞一年就可能消耗掉一整塊固態硬碟,引發強烈不滿。