Sakana AI 提出 DiffusionBlocks:將殘差網路轉換為獨立可訓練去噪模組的區塊式訓練框架
重點摘要
來自 Sakana AI 與東京大學的研究者提出 DiffusionBlocks,該方法將基於 Transformer 的網路逐一區塊進行訓練。訓練記憶體需求可降低至原來的 1/B(B 為區塊數量),且在多種架構下維持相同效能。針對神經網路訓練中的記憶體問題,傳統端到端反向傳播需儲存每層的中間激活值,記憶體消耗隨網路深度線性增長。現有技術如激活檢查點雖能減少激活記憶體,卻無法降低參數、梯度或優化器狀態的記憶體需求。以 Adam 優化器為例,每層仍需為參數、梯度等配置記憶體。
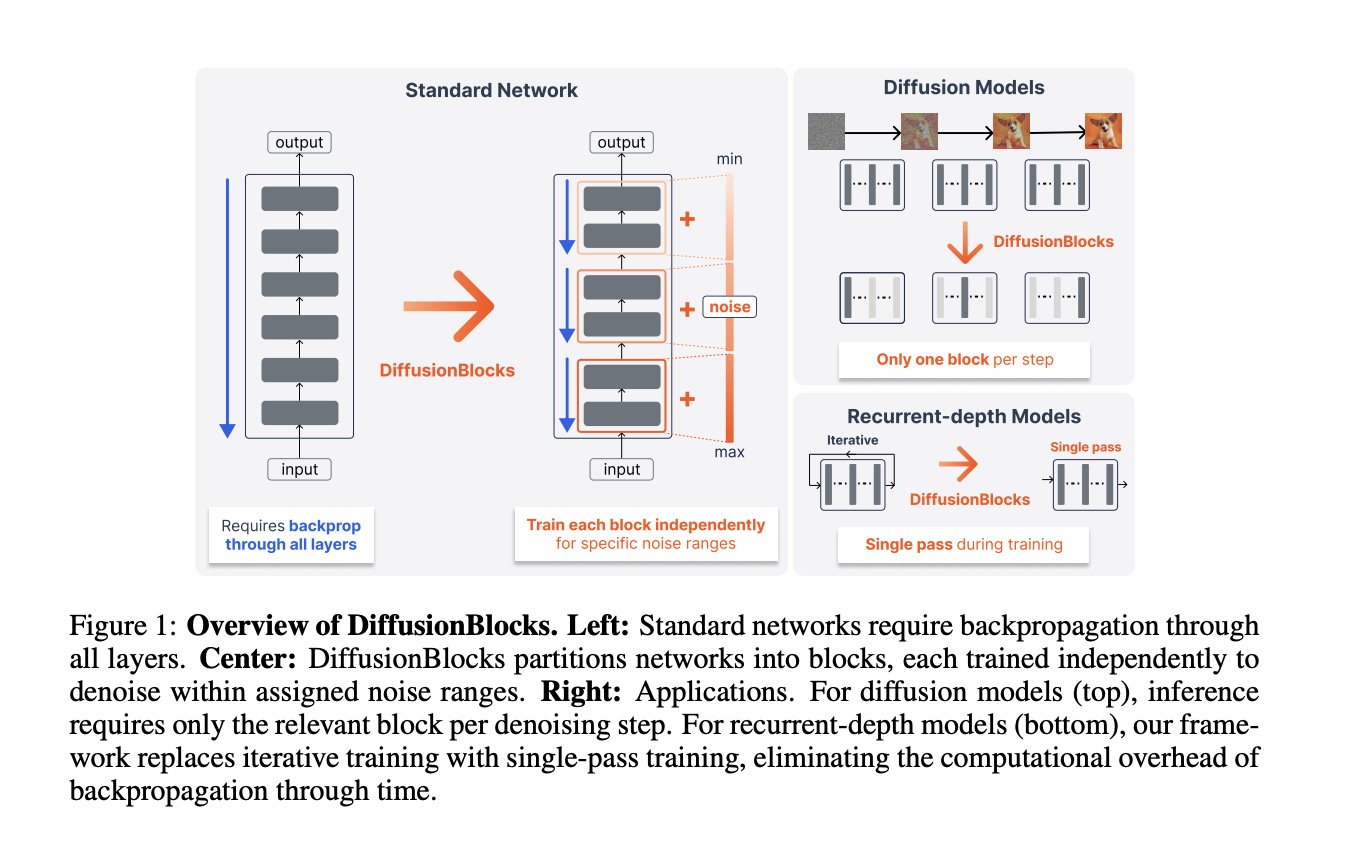
Researchers from Sakana AI and the University of Tokyo propose DiffusionBlocks. It trains transformer-based networks one block at a time. Training memory is reduced by a factor of B, where B is the number of blocks. Performance is maintained across diverse architectures. The Memory Problem in Neural Network Training End-to-end backpropagation requires storing intermediate activations across every layer. Memory consumption grows linearly with network depth. As models grow deeper, this becomes a significant training bottleneck. One existing technique, activation checkpointing, reduces activation memory by recomputing activations on demand. However, it does not reduce memory for parameters, gradients, or optimizer states. With the Adam optimizer, each layer requires memory for parameters, gradients, and two optimizer states (momentum and variance). This totals 4 times the parameter size per layer, unchanged by activation checkpointing. Block-wise training offers a different approach. Partitioning a network into B blocks and training each independently reduces memory to roughly 1/B. The reduction is proportional to the number of blocks. The challenge is defining a principled local objective for each block that still produces a globally coherent model. Prior approaches like Hinton’s Forward-Forward algorithm and greedy layer-wise training rely on ad-hoc local objectives. They consistently underperform end-to-end training and are largely limited to classification tasks. DiffusionBlocks addresses both the theoretical gap and the limited applicability of prior methods. https://arxiv.org/pdf/2506.14202 The Core Idea: Residual Connections as Euler Steps The key insight builds on an established connection in the literature. Residual networks update each layer input via zℓ=zℓ−1+fθℓ(zℓ−1)zℓ = zℓ−1 + fθℓ (zℓ−1) . This corresponds to Euler discretization of ordinary differential equations. The research team show these updates correspond specifically to the probability flow ODE in score-based diffusion models. In the Variance Exploding (VE) formulation, the reverse diffusion process follows: d𝐳σdσ=−σ∇𝐳logpσ(𝐳σ) \frac{\mathrm{d}\mathbf{z}_\sigma}{\mathrm{d}\sigma} = -\sigma \nabla_{\mathbf{z}} \log p_\sigma(\mathbf{z}_\sigma) Applying Euler discretization to this equation produces an update rule that structurally matches the residual connection update. A stack of residual blocks can be interpreted as discretized denoising steps. The steps span a noise level range [𝞂min, 𝞂max]. In score-based diffusion models, the score matching objective can be optimized independently at each noise level. This means each block can be trained independently, using only its own local objective. No inter-block communication is needed during training. Converting a Network: Three Steps Converting a standard residual network to DiffusionBlocks requires three modifications: Block partitioning: Split the L-layer network into B blocks. Each block contains a contiguous group of layers. Noise range assignment: Define a noise distribution pnoise and a noise range [𝞂min, 𝞂max]. Partition this range into B intervals and assign one interval to each block. The research team recommend a log-normal distribution for pnoise. Noise conditioning: Extend each block’s input to include a noisy version of the target. Add noise-level conditioning via AdaLN (Adaptive Layer Normalization). Each block learns to predict the clean target from its noisy version within its assigned noise range. During training, a single block is sampled per iteration. The other blocks are not computed. Memory consumption corresponds to L/B layers, not all L layers. Equi-probability Partitioning A naive uniform partition divides [𝞂min, 𝞂max] into equal intervals. This ignores the varying difficulty of denoising across noise levels. Intermediate noise levels contribute the most to generation quality under the log-normal training distribution. DiffusionBlocks uses equi-probability partitioning instead. Boundaries are chosen so each block handles exactly 1/B of the total probability mass under pnoise. Blocks assigned to intermediate noise levels receive narrower intervals. Blocks handling extreme noise regions receive wider intervals. In ablation studies on CIFAR-10 using DiT-S/2, block overlap was disabled to isolate each component. Equi-probability partitioning achieved FID of 38.03 versus 43.53 for uniform partitioning (lower is better). Both used a uniform layer distribution of [4,4,4] across 3 blocks. Experimental Results The research team evaluated DiffusionBlocks across five architectures spanning three task categories. All results compare DiffusionBlocks (trained block-wise) against the same architecture trained with end-to-end backpropagation. ArchitectureDatasetMetricBaselineDiffusionBlocksMemory ReductionViT, 12-layer, B=3CIFAR-100Accuracy (higher is better)60.25%59.30%3xDiT-S/2, 12-layer, B=3CIFAR-10FID test (lower is better)39.8337.203xDiT-L/2, 24-layer, B=3ImageNet 256×256FID test (lower is better)12.0910.633xMDM, 12-layer, B=3text8BPC (lower is better)1.561.453xAR Transformer, 12-layer, B=4LM1BMAUVE (higher is better)0.500.714xAR Transformer, 12-layer, B=4OpenWebTextMAUVE (higher is better)0.850.824xHuginn recurrent-depthLM1BMAUVE (higher is better)0.490.70~10x compute Forward-Forward comparison: On CIFAR-100, the Forward-Forward algorithm achieved only 7.85% accuracy under the same ViT architecture. This highlights the gap between ad-hoc contrastive objectives and the score matching objective used by DiffusionBlocks. DiT inference efficiency: For diffusion models, each denoising step during inference activates only one block. A 12-layer DiT with B=3 uses only 4-layer evaluations per denoising step. This is a 3x inference compute reduction versus running all 12 layers. Huginn training: Huginn applies the same 4-layer recurrent block recurrently. It uses stochastic recurrence depth averaging 32 iterations. Training uses 8-step truncated backpropagation through time (BPTT). DiffusionBlocks replaces this with a single forward pass per training step. The K-iteration inference procedure is kept unchanged. The 32x iteration reduction outweighs the 3x longer training schedule. DiffusionBlocks trains for 15 epochs versus Huginn’s 5 epochs. Total compute is reduced by approximately 10x. OpenWebText results: On OpenWebText, DiffusionBlocks MAUVE was 0.82 versus 0.85. Generative perplexity under Llama-2 was 14.99 versus 15.05. Results on this dataset were mixed, with some metrics slightly worse than the baseline. Masked diffusion partitioning: For masked diffusion models, block partitioning targets the masking schedule rather than continuous noise levels. Each block handles an equal decrement in the unmasking probability alpha(t), ensuring balanced parameter utilization across blocks. Comparison with NoProp NoProp is a concurrent work that uses a diffusion framework for backpropagation-free training. It is evaluated only on classification tasks using a custom CNN-based architecture. It does not provide a procedure for applying the method to other architectures or tasks. MethodContinuous-timeBlock-wiseAccuracy on CIFAR-100BackpropagationNoNo47.80%NoProp-DTNoYes46.06%NoProp-CTYesNo21.31%NoProp-FMYesNo37.57%DiffusionBlocks (ours)YesYes46.88% DiffusionBlocks is the only method combining a continuous-time formulation with block-wise training. It stays within 1 percentage point of the end-to-end backpropagation baseline. Strengths and Weaknesses Strengths: Principled theoretical grounding via score matching, not ad-hoc local objectives Works across five distinct architectures without task-specific modifications B× training memory reduction, proportional to the number of blocks For diffusion models, inference compute is also reduced by B× during generation Equi-probability partitioning significantly outperforms uniform partitioning (FID 38.03 vs 43.53 on CIFAR-10) Replaces K-iteration BPTT in recurrent-depth models with a single
Related
相關文章
Liquid AI Introduces LFM2.5-Embedding-350M and LFM2.5-ColBERT-350M: Dense Bi-Encoder and Late-Interaction Models for Fast Multilingual Search Across 11 Languages
This week, Liquid AI released two new retrieval models. They are LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M. Both hold 350M parameters. Both are the first bidirectional members of the LFM family. They build on LFM2.5-350M-Base, released in March. The pair targets fast multilingual and cross-lingual search across 11 languages. Their footprint is small enough to run almost anywhere. Both are available now on Hugging Face under the LFM Open License v1.0. LFM2.5 Retrievers The two models share one backbone but represent text differently. LFM2.5-Embedding-350M is a dense bi-encoder. It turns each document into a single vector. Pick it when you want the fastest search and the smallest, cheapest index. LFM2.5-ColBERT-350M is a late-interaction model. It converts each token into a vector rather
Perplexity Launches Brain, a Self-Improving Memory System That Builds a Context Graph of an Agent’s Work and Learns Overnight
Most AI memory remembers the user. It stores your preferences, your tastes, and your role. Perplexity is taking a different path. Today, Perplexity launched Brain, a self-improving memory system for its agent product, Computer. Brain does not focus on remembering you. It remembers what the agent did. That reframes what memory in AI is for. What is Perplexity‘s Brain Brain is a self-improving memory system. It builds a context graph of the work Computer performs. At set intervals, such as overnight, Brain reviews that graph. It then teaches itself how to do the work better. The idea is straightforward. The more work you do, the more efficient Brain makes your Computer. Brain is rolling out today to Perplexity Max and Enterprise Max subscribers in Research Preview. Two Axes of AI Memory Perp

智譜新高,MiniMax承壓,“大模型雙雄”命運殊途
這篇消息聚焦「智譜新高,MiniMax承壓,“大模型雙雄”命運殊途」。原始導語提到:大模型在被市場重新定價 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

華為昇騰 0 Day 支持智譜 GLM-5.2 模型,提供全面推理優化
華為昇騰 AI 宣佈在智譜開源 GLM-5.2 大模型當天即完成深度推理優化。通過 MOE 大融合算子、通信計算融合、高併發調度等七項關鍵技術,顯著提升編程和長程任務的處理效率,現已支持 A3 系列產品部署。#AI 大模型# #國產算力#
企業AI轉型再添利器:青雲科技算力雲接入 MiniMax-M3 模型
企業AI落地面臨高效低成本難題。青雲科技旗下基石智算平臺接入國產開源大模型MiniMax-M3,提供新算力支持。MiniMax-M3以卓越上下文處理能力等三大核心技術見長,依託自研架構,助企業便捷部署AI業務。
阿里開源統一科學大模型 LOGOS,僅用五十六分之一參數超越微軟
阿里 ATH-Token Foundry 聯閤中國人民大學高瓴人工智能學院開源科學基礎模型 LOGOS。該模型採用統一科學語法與純序列建模範式,在六大科學任務上匹配或超越傳統專用方法。其中 LOGOS-1B 僅 1B 參數,即展現出極高效率,性能超越參數量達 8×7B 的微軟模型。