Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
重點摘要
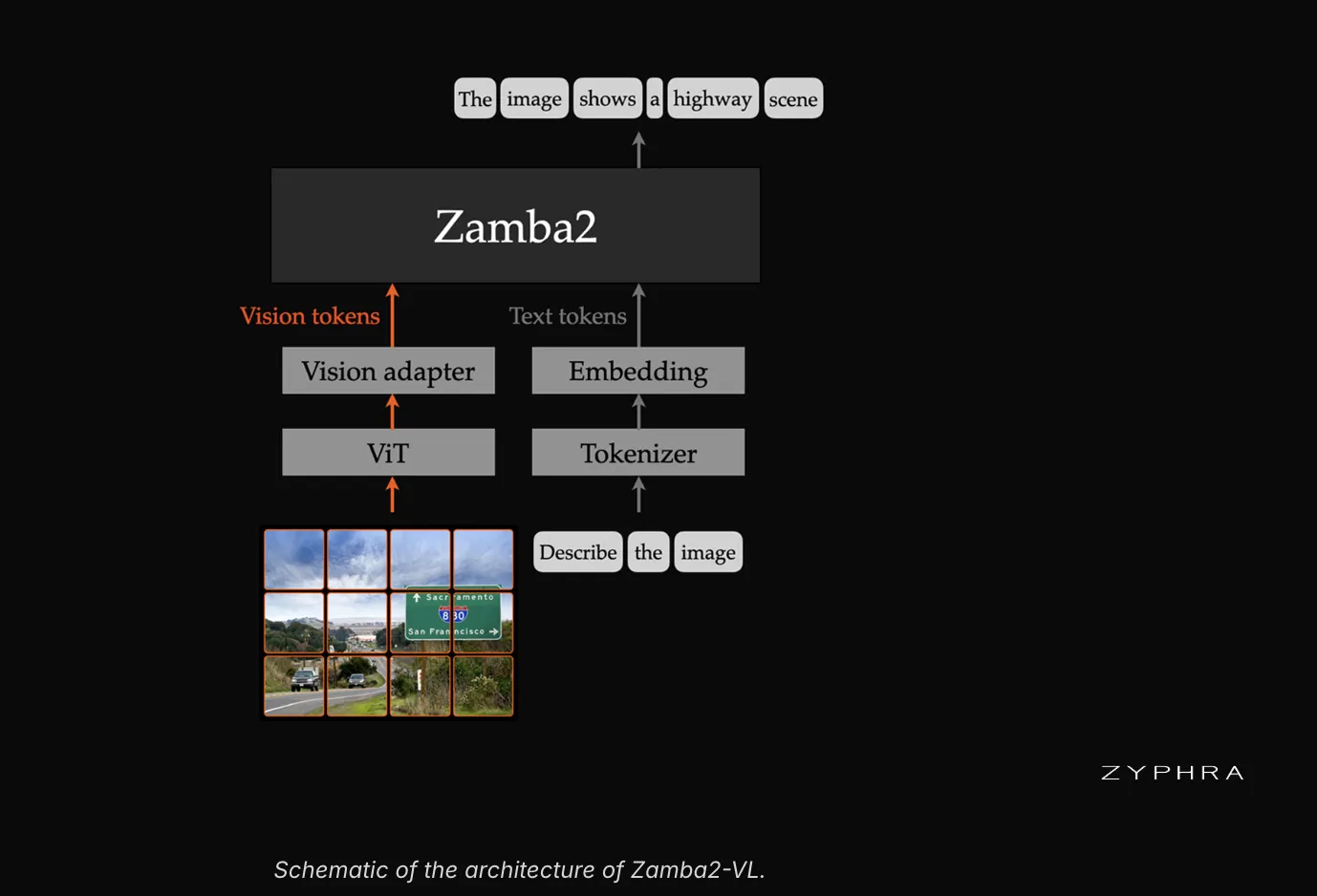
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. Each model is built on the Zamba2 hybrid SSM–Transformer backbone. Vision-language models (VLMs) read images and text together. They answer questions about charts, documents, and photos. Most open VLMs use a dense Transformer as the language model. Zamba2-VL replaces that with a hybrid state-space design. The goal is competitive accuracy at lower latency. What is Zamba2-VL Zamba2-VL follows the now-standard LLaVA-style VLM template. A pre-trained vision encoder turns image patches into features. A lightweight MLP adapter projects those features into the language model’s space. The language model then reads an interleaved sequence of vision and text tokens.
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. Each model is built on the Zamba2 hybrid SSM–Transformer backbone. Vision-language models (VLMs) read images and text together. They answer questions about charts, documents, and photos. Most open VLMs use a dense Transformer as the language model. Zamba2-VL replaces that with a hybrid state-space design. The goal is competitive accuracy at lower latency. What is Zamba2-VL Zamba2-VL follows the now-standard LLaVA-style VLM template. A pre-trained vision encoder turns image patches into features. A lightweight MLP adapter projects those features into the language model’s space. The language model then reads an interleaved sequence of vision and text tokens. The models support single and multi-image understanding and grounding. Zyphra pairs each Zamba2 backbone with the Vision Transformer from Qwen2.5-VL. That encoder was chosen for two specific properties. It uses 2D rotary position embeddings and native dynamic-resolution processing. A two-layer MLP adapter connects the encoder to the backbone. https://www.zyphra.com/our-work/zamba2-vl The Architecture The Zamba2’s backbone is where the design diverges from typical VLMs. It is a hybrid of Mamba2 state-space layers and shared transformer blocks. The Mamba2 layers run in linear time with a fixed-size state. A small number of shared attention layers are interleaved between them. Each shared block carries a unique LoRA adapter at each layer. The Mamba2 layers carry the bulk of computation cheaply. The shared attention layers preserve in-context retrieval that pure-SSM models give up. The hybrid trades full-attention expressivity against state-space efficiency. Zamba2-VL uses the Mistral v0.1 tokenizer. It was trained on 100B tokens of vision-text and pure-text data. That data was sourced from open web datasets. https://www.zyphra.com/our-work/zamba2-vl Model Quality and Benchmarks The research team evaluated Zamba2-VL across 14 benchmarks. These span chart, diagram, and document understanding. They also cover general perception, reasoning, and visual counting. All scores come from Zyphra’s evaluation harness, which is based on VLMEvalKit. The report compares against the Molmo2, Qwen3-VL, and InternVL3.5 families. EvalZamba2-VL-2.7BInternVL3.5-2BQwen3-VL-2BMolmo2-4BQwen3-VL-4BDocVQA (test)90.989.493.387.895.3ChartQA (test)79.681.678.786.181.8OCRBench73.683.484.162.084.1CountBenchQA87.570.087.991.287.3PixMoCount (test)82.532.855.787.089.2MMMU (val)37.749.940.948.851.4MathVista (mini)51.061.451.856.563.6 InternVL3.5-2B and Qwen3-VL-2B are similar in size. Molmo2-4B and Qwen3-VL-4B are larger. The pattern is uneven and worth understanding. Counting is the strongest category. Zyphra reports Zamba2-VL-1.2B at 62.5 on PixMoCount. That compares with 32.8 for InternVL3.5-1B and 17.7 for PerceptionLM-1B. Document understanding also holds up, with DocVQA at 90.9 for the 2.7B model. The model lags larger baselines on knowledge-heavy reasoning, such as MMMU and MathVista. Why Inference is Faster Inference is where Zamba2-VL shows its main advantage. Transformer attention scales quadratically with sequence length. Multimodal inputs make sequences long very quickly. A single high-resolution image can add several thousand vision tokens. A short video clip can produce tens of thousands of tokens. Zamba2-VL avoids the growing KV cache of attention. It inherits near-linear-time prefill and a fixed-size recurrent state. On a 32k-token prefill, it leads on the score-versus-TTFT plot. No Transformer VLM in the comparison matched its score at similar latency. The latency gap is at least an order of magnitude. The efficiency advantage is largest at the 1.2B and 2.7B scales. That is the range targeted for on-device and edge deployment. Use Cases With Examples The practical question is where this fits. Document and form extraction benefits from the strong DocVQA results. Think invoice parsing or receipt digitization at scale. Retail and inventory counting maps to the PixMoCount and CountBenchQA strengths. Grounding support enables pointing to objects in product or UI images. On-device assistants benefit from the low time-to-first-token. The 1.2B model targets phones and edge boxes. Long visual inputs, like multi-page PDFs, gain most from linear-time prefill. Getting Started The three models live in the Zyphra Zamba2-VL collection on Hugging Face. Inference runs through Zyphra’s transformers fork, based on transformers v4.57.1. The optimized Mamba2 kernels need a CUDA GPU for good latency. Install the fork and its core dependencies: Copy CodeCopiedUse a different Browserpip install "transformers @ git+https://github.com/Zyphra/transformers.git@zamba2-vl" pip install qwen-vl-utils==0.0.2 pip install flash_attn Optimized Mamba2 kernels need two more packages: Copy CodeCopiedUse a different Browserpip install --no-build-isolation "causal-conv1d @ git+https://github.com/Zyphra/z-causal-conv1d.git@zamba2-vl" pip install --no-build-isolation "mamba-ssm @ git+https://github.com/Zyphra/mamba.git@zamba2-vl" Then load the model and run a single-image query: Copy CodeCopiedUse a different Browserfrom transformers import Zamba2_VLForConditionalGeneration, Zamba2_VLProcessor import torch from PIL import Image from qwen_vl_utils import process_vision_info import requests device = "cuda" processor = Zamba2_VLProcessor.from_pretrained("Zyphra/Zamba2-VL-2.7B", temporal_patch_size=1) model = Zamba2_VLForConditionalGeneration.from_pretrained( "Zyphra/Zamba2-VL-2.7B", device_map=device, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2", ) url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw) question = "What do you see in the image? Give us some detail." num_img_tokens = 3400 conversation = [ {"role": "user", "content": [ {"type": "image", "image": image, "max_pixels": num_img_tokens * 28 * 28, "min_pixels": 10 * 28 * 28}, {"type": "text", "text": question}, ]}, ] prompt = processor.apply_chat_template(conversation, add_generation_prompt=True) images, _ = process_vision_info(conversation) inputs = processor(text=prompt, images=images, add_special_tokens=True, return_tensors="pt") inputs = {key: value.to(device) for key, value in inputs.items()} outputs = model.generate(**inputs, max_new_tokens=100) print(processor.tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:])) Swap the model ID for Zamba2-VL-1.2B or Zamba2-VL-7B to change scale. Strengths and Weaknesses Strengths: First open VLM family on a fully open hybrid SSM–Transformer LLM, per Zyphra. About an order of magnitude lower time-to-first-token than comparable Transformer baselines. Strong visual counting and competitive document understanding. Three sizes cover edge, mid, and 7B-class deployment. Apache 2.0 license with public weights and working inference code. Weaknesses and Challenges: Released as a research artifact. Lags larger models on knowledge reasoning like MMMU and MathVista. Lower OCRBench than same-size Qwen3-VL and InternVL3.5. Optimized kernels need a CUDA GPU; CPU paths are slow. Deployment requires self-hosting from the released code. Key Takeaways Zamba2-VL ships at 1.2B, 2.7B, and 7B parameters under Apache 2.0. The backbone pairs Mamba2 state-space layers with a few shared transformer blocks. Time-to-first-token drops about an order of magnitude versus comparable Transformer VLMs. Counting and document understanding are strengths; knowledge reasoning lags. Weights and working inference code are public on Hugging Face and GitHub. Marktechpost’s Interactive Explainer #mtp-zamba2vl-explainer *{box-sizing:border-box!important;margin:0;padding:0} #mtp-zamba2vl-explainer hr,#mtp-zamba2vl-explainer p:empty,#mtp-zamba2vl-explainer del,#mtp-zamba2vl-explainer s{display:none!important} #mtp-zamba2vl-explainer{ background:#0d0d0d!important;color:#e8e8e8!importan
Related
相關文章

AI成績單背後,藏著一位華人“出題人”
這篇消息聚焦「AI成績單背後,藏著一位華人“出題人”」。原始導語提到:AI,你需要向虎證明自己很聰明。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

35歲被AI“頂替”,他用26萬的判決書扯下企業的遮羞布
這篇消息聚焦「35歲被AI“頂替”,他用26萬的判決書扯下企業的遮羞布」。原始導語提到:不是AI太強,是藉口太好用。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

別被不靠譜服務商忽悠,GEO優化沒有捷徑
這篇消息聚焦「別被不靠譜服務商忽悠,GEO優化沒有捷徑」。原始導語提到:怎麼重建GEO行業信任,避免踩坑? 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

我把昨晚的夢輸入AI,它居然直接把我拉進去玩兒了一把?!
這篇消息聚焦「我把昨晚的夢輸入AI,它居然直接把我拉進去玩兒了一把?!」。原始導語提到:創作者的終極玩具來了 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

美國AI狂飆,亞洲搶先吃飽
這篇消息聚焦「美國AI狂飆,亞洲搶先吃飽」。原始導語提到:亞洲,正在成為全球算力基礎設施製造中心。 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。

馬斯克花600億美元,買了箇中國模型底座的代碼編輯器
這篇消息聚焦「馬斯克花600億美元,買了箇中國模型底座的代碼編輯器」。原始導語提到:錢的大頭,又讓別人賺走了 從 AI 情報角度來看,這類內容值得關注其背後的技術進展、產品落地、產業競爭與後續市場影響。